
Nearly 100% error rate: our first major outage
Alon Ashkenazi, Solid's VP of Engineering, takes us through Solid's first major outage.

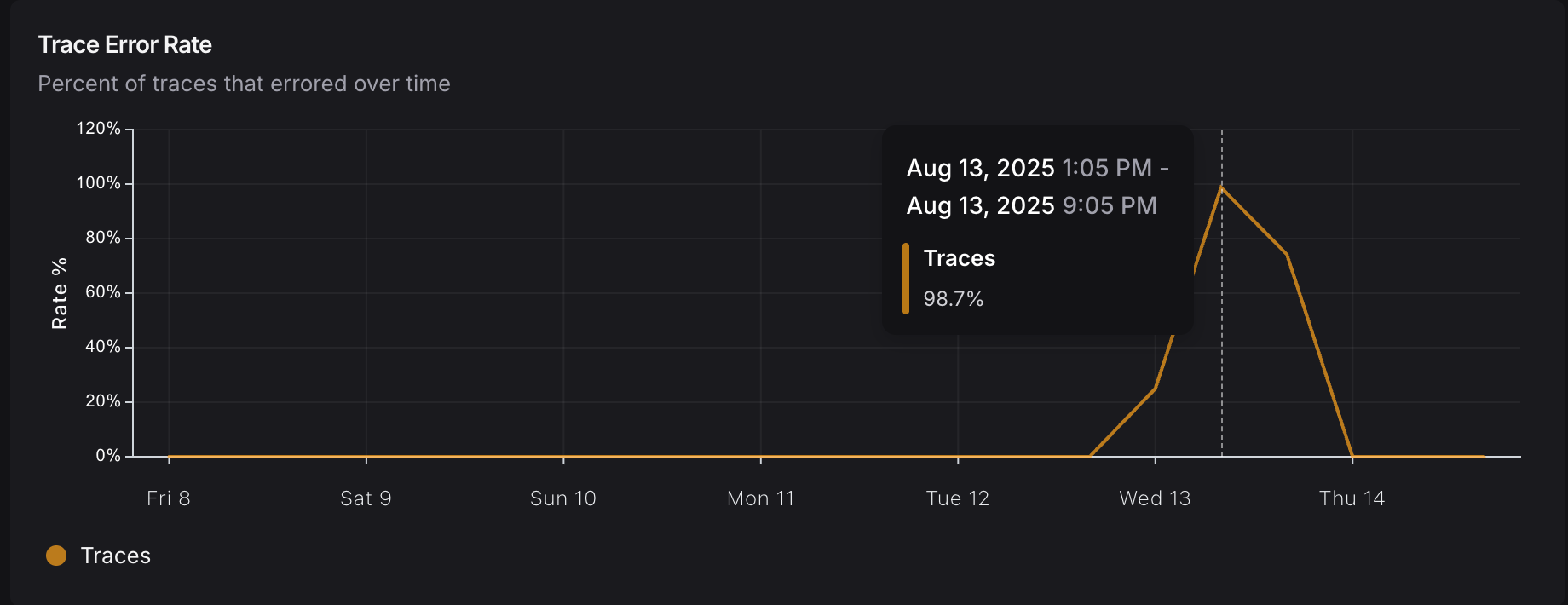
We monitor our platform 24/7 through a variety of means. The chat engine within it, the main interface on our platform, is monitored via LangSmith. On Wednesday, Aug 13th 2025, we started getting flooded with alerts from the platform - chat interactions are failing. Almost 100% of them:
Since we have a pretty robust logging and observability tools implemented, we could easily find the culprit. The logs were full with the error message: “the requested model is currently experiencing high load, please try again later”.
Every growing startup experiences its first “oh moment” where services are down and the engineering team scrambles to resolve it. This was ours.
As a reminder - Solid’s platform is used by companies all over the world to help them document all of their data assets (tables, views, dashboards, queries, metrics, etc) and then search through them in a chat manner (or make available to other AI services via API). The chat helps the users think through how to implement or complete a certain analytics task. (it doesn’t do it for them, yet)
If the chat doesn’t work, that’s the main interface down. That’s bad.
So, what broke?
As we shared in the past, we use an agentic platform with LangGraph. Whenever a user types a prompt, like “help me analyze last month’s campaign to raycatchers”, it goes through a complicated set of steps before an output is returned.
One part of that process (usually, but not always), involves doing a semantic search on the lists of assets we’ve mapped out and documented across the user environment.
To do this, we use Cohere through the Azure AI services. We picked Cohere, because in our testing, it was the best (see some here, and here). It worked really, really, well. Until last week - when it stopped working.
Without any major change in our code or behavior, the Cohere model on Azure started throwing errors. 😱
Consider the example I shared above - as part of the process, we use the Cohere model to search through our assets for things that are semantically close to both “marketing campaigns” and “RayCatchers” (a term used in our demo environment). The team at Cohere have pretty good docs, and explain how this works clearly.
This search should be pretty quick, because we prepare all the embeddings for the assets in advance (when we scan for the assets - daily and weekly) and so it should just be simple mathematical calculations that happen during the search.
But, if the Azure AI service itself is having issues, it throws a wrench into everything. It causes almost all of the chats to error out, as you can see on the top of this page.
Immediate path: redundancy of calls
We run in Azure’s East region. All the customer data is processed there in line with our security policies and protocols, which we share under the SOC2 Type II audit we go through regularly.
Our first step, was to assume that something is happening in Azure’s East region around the Cohere model and we need to build more redundancy. The Azure services status page showed all green, no incidents. We didn’t know what was going on there, but could see something was awry.
So - we started sending all Cohere semantic search requests to both the East and North regions in parallel. Our hope was that we would hit different compute resources, and whatever would respond first we can use.
Initially, the North region experienced the same issues as the East region (which was surprising). Over the course of the following hours (after identifying the issue), we noticed that Cohere searches in the North region started stabilizing.
We still don’t know what caused the issue on their end. But, this patch, and whatever they did behind the scenes, brought us back to stability by Friday morning.
Secondary path: redundancy of models
It’s possible that the specific issue with the Cohere model within Azure AI Search will return. So over the following days, we implemented another semantic search model - text-embedding-3-small. Unfortunately, it’s not as accurate as the Cohere model we use (for our purposes), and so we do so reluctantly.
Still, you need to have a fall back for every service / technology you use in case it misbehaves.
Enabling the secondary path means that now when we process assets (not during the chat, rather the daily and weekly processing), we need to generate embeddings with two models. That makes things slightly more complicated, and also increases our compute usage ($$) and time. Not ideal, but necessary.
Now, if Cohere’s models on Azure AI start throwing issues again, we can simply switch to the backup semantic model. It will reduce accuracy, but keep the service going.
Tertiary path: redundancy of services
We’ve built our entire platform on Azure. We started with their “black box” for AI, then we broke it out to a few services in a deterministic flow, and then we switched to an agentic platform. All this time, we stayed completely on the Azure platform. It’s easier to build there, and makes sense from a cost perspective.
However, things happen. Sometimes there are outages in the underlying services, and there’s only so much you can run in parallel across cloud regions.
Before this outage, we were wondering if we should have backup services outside Azure - such as using the OpenAI and Anthropic APIs directly. Of course, we will do so in a secure manner and only if they meet the same data protection and security requirements we enforce within Azure.
This outage accelerated our thinking - we will have a happy path, where everything runs within Azure East and using the precise models we want. But we will also have backup paths, where we run across regions, or even send API calls outside of Azure entirely.
It makes things more complicated for us, and more costly. But it increases the reliability of our platform, which is so key to our users.