
Solid's Leap to an Agentic Platform: Unlocking New AI Capabilities
Solid recently made the switch to an Agentic Platform and the company's VP of Research and VP of Engineering share why and how.


At Solid, we recently completed our move to an agentic platform. In this blog post, we’ll detail the why and how, with future blog posts planned for diving deeper into certain aspects. We’re sharing this in hope that it will help others building agentic platforms, considering various options.
Why move to an agentic platform now?
Because Jason Ganz of dbt Labs said it’s cool. j/k.
As we’ve shared on this substack in the past, we initially started with a Microsoft Azure-supplied black box. Then, we broke out of the black box. In the following months, we expanded our solution to become a multi-stage process.
And now, just a few months later, we’re migrating to an agentic platform.
We’re a deeply experienced team, with two decades of software and research experience per person. In all that experience, we’ve never seen a company need to move so quickly from one implementation to the next.
Until 2024, our experiences at new startups were quite consistent. We would build some monstrous monolithic application in order to ship as fast as possible. Then, after a year or two, and millions in ARR, it would become unwieldy, and we would start breaking it into smaller pieces. (remember micro-services?)
However, in the age of AI, timelines for everything have compressed. The expectations the users have of your offering, its capabilities, accuracy, and performance, are skyrocketing. Therefore, what would have survived a year or two in the past, cannot anymore. You need to continuously run as fast as you can.
In our case, we’re been shipping new capabilities and intelligence within our chat engine at break-neck speed, and the monolithic, four-stage solution, just doesn’t cut it anymore.
For example, consider a user asking: “Where can I find data for the email campaigns we ran for different LLS levels?”.
In our four-stage solution, it would first translate “LLS” to what the term means within the customer environment (an internal acronym), then it would run a search across multiple RAGs to find the right data assets.
Now, if it found any unique glossary terms within those data assets (like “RayCatcher”, another internal term within our demo scenario here), it wouldn’t know what to do with it.
The reason? Glossary was stage one. It isn’t inserted also at stage 3. Nor should it be, because usually it’s not needed, and inserting it would slow down the response.
But how do we handle these cases? The four-stage process couldn’t cut it.
So we needed flexibility. The kind of flexibility where you can run your different capabilities in any order, sometimes running the same capability multiple times at different slots along the process to help get a better result.
We wanted an ability to more easily define and test discrete functions. While you have unit-tests, etc, there is a lot of value in compartmentalizing the functions a lot better so that researchers and developers can easily spin them up in their own environment, make changes, run tests, etc.
We were hitting LLM limits. Our main prompt was getting big, and complicated. We could see our AI get confused at times… not knowing what to do in some cases and give some pretty weird answers. We also realized that different tasks require different models, sometimes provided by different vendors, and we needed to be able to do that.
With the number of users on our platform growing rapidly, we were missing a strong observability solution that could peek deep within the stages our AI was going through. Knowing what each request demands, how long it takes and why, is crucial.
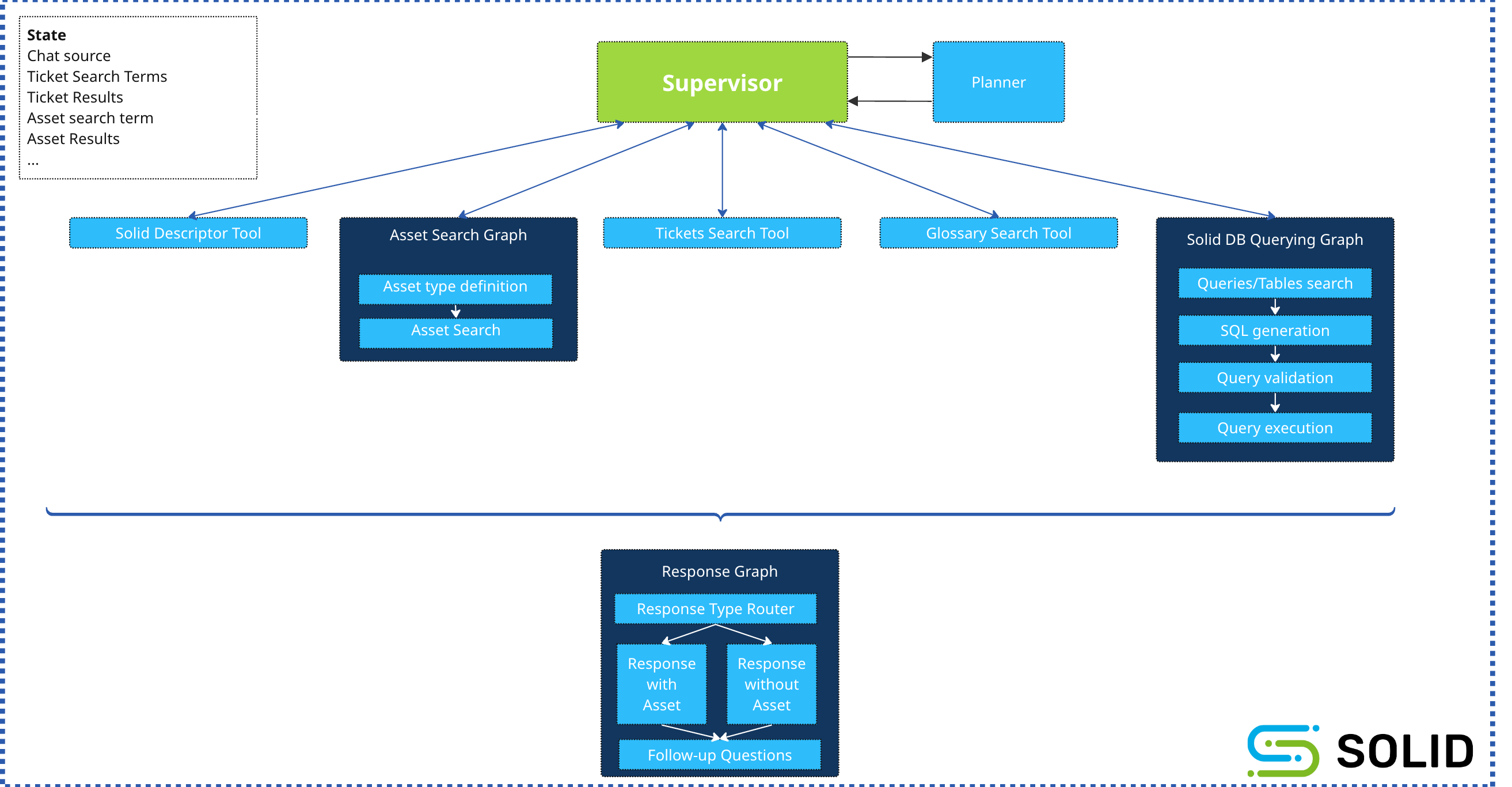
How does the Solid agentic platform look like?
At a high level, it’s pretty simple:
There’s a Supervisor, which receives the user input (or from another entity, like another AI or API call).
The Supervisor is aware of all of the tools it has at its disposal.
It constructs a plan of action - how to utilize those tools, in what order, to provide the optimal result. It can choose to use the same tool multiple times at different steps along the way.
The Supervisor evaluates the execution at every step (after every tool completes), and can choose to change its plan (replanning).
All of this planning and replanning is done through the use of an LLM.
NOTE: We attempted to use LangChain’s own Supervisor package, but decided it wasn’t a good fit and went with our own. This will be the subject of another post.
There are tools - each tool can do something:
An Asset Search Tool, which spans a long set of data sources, documenting data assets in the customer environment (describing tables, views, columns, dashboards, reports, metrics, SQL queries, etc).
A Glossary Tool, which helps the AI understand what certain acronyms and terms mean.
A Solid Meta Description Tool, which actually knows what Solid is, what the platform is capable of, etc.
JIRA Ticket Search Tool, which can search through the JIRA tickets in the customer environment that pertain to data engineering and analytics tasks.
Slack Search Tool, which does something similar, for a set of Slack channels within the customer’s workspace.
Solid-DB Query Tool, which allows the AI to actually query our own database. Useful when the user is asking for a list of objects with certain attributes, a search that may be more efficient and productive than a RAG-based search.
After the plan execution completes, the flow always gets handed to a Response Graph - which is responsible for validating the result and structuring the response the chat sends back.
This also takes into consideration various interface limitations. For example, if the chat started from a DM to our Slackbot, then the response is limited to 4,000 characters and certain visual features.
Across all of these stages, there’s a State. The State is initialized at first with information about the request, who made it, what tenant and user, and so forth. Then, each time a tool completes its execution, the State is updated with the tool’s results, so that other tools can take it into consideration as well as the Supervisor. Over time, the State gets quite big, bringing forth its own challenges.
Some additional bonuses
Our CI/CD is now capable of testing each tool, plus the Supervisor, and the entire flow, in a more thorough manner. This helps identify deviations and regressions. We can also run longer-form tests once in a while when more major changes are needed. Both use cases employ LangSmith, which has been incredibly helpful in getting better visibility into how our platform operates. It took our evals mechanism a major step forward.
Each tool can pick which LLMs it wants to use… or not use at all. This is a major advantage, as we all know there are advantages and disadvantages to each model (accuracy / results / speed / cost) that must be taken into account per task.
The accuracy and relevancy of the responses from the chat has improved drastically. Giving the AI more freedom has resulted in massive improvements. Instead of trying to chase each possible use case (and there are many, as users are still figuring out what is possible), we’re letting the AI figure it out. Not bulletproof, but we’re seeing real improvement already.
The result
Even with the limited time we’ve had this new engine on the road, it’s already solved things we couldn’t do before. Our pace of development is accelerating (even faster!) and we’re able to offer new capabilities we couldn’t before.
Remember that example with LLS and RayCatcher above? Now with the agentic platform, it understands what LLS means (as did the previous one), searches for the right assets, goes through their documentation to identify internal terms (like RayCatcher), run those terms through the Glossary Tool, and use it to expand its asset search even further.
The Response Graph takes this extra level of information a step further by explaining to the user what the terms mean and how they relate to the different levels of LLS, as requested.
This results in a far more complete answer to the user, deeper and with more value.
We also are seeing AI solving problems it couldn’t in the past, such as figuring out what something means (from the Glossary Tool) even the term popped up late in the flow.
We’re truly proud of the Solid AI and look forward to bringing forward even more innovation and value to our users.
FAQ
Why LangGraph?
It is the most mature of all agentic SDKs we’ve evaluated, with a truly robust community. It fit our needs like a glove and we are tremendously happy with it. LangSmith is a HUGE benefit, too.What is the difference between an Agent and a Tool?
An Agent is a Tool that can only use an LLM - it provides it with a prompt and returns the results back through the State. A Tool can do whatever it wants - query a DB, run an API, generate SQL - with or without an LLM. It’s up to the Tool.
Stay tuned for our future blog posts digging further into this new platform. There’s so much to share, we’re excited already! Feel free to comment below with any thoughts or questions you may have.
 | A guest post by
|