
Breaking the Black Box: Lessons from Azure AI Services for Chat Implementation
Solid's VP of Research, Maya Bercovitch, shares our experience using Azure's AI services for the first iteration of the Solid platform

At Solid, we focus on helping analysts work smarter and faster. As part of this, we’ve been exploring ways to improve how analysts define research tasks received from business stakeholders, as well as finding the right data to use.
Just like any good startup, we started with a very early version to assess viability and interest from potential customers. That early version has evolved considerably since, of course, and we thought it would be interesting to share our learnings with one piece of the puzzle - Azure AI.
Azure AI’s “Use your own data”
Azure offers a quick-start guide for creating a chat experience based on Azure Open AI service, with the ability to use a Retrieval-Augmented Generation (RAG) that is implemented as an Azure AI Search index.
This framework includes the implementation of the following logics:
Turn user questions into search terms/queries.
Execute search and get relevant documents from the RAG.
Provide detailed answers enriched with relevant data.
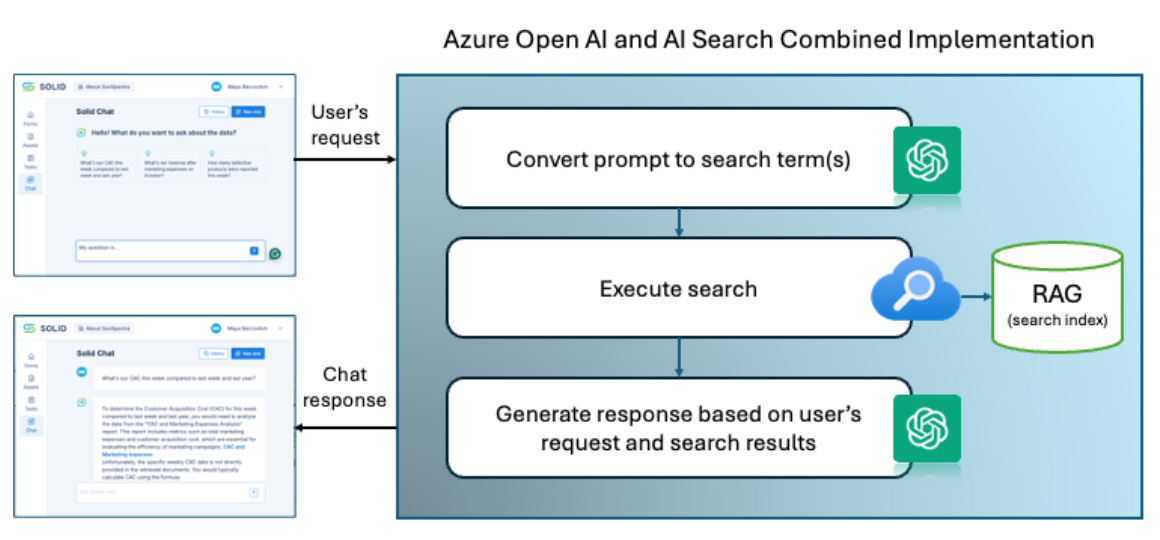
If you are in the early phase of a startup, where you want to ship quickly and get feedback before building more robust and complicated solutions, this solution might be the point to start. We started this way and managed to create a good demo experience in a very short time. After our solution evolved, we found areas where we needed more flexibility and control than available by this service.
In this blog post we’ll describe some of the important implementation details, and cover the limitations that we encountered which made us move forward to a more sophisticated chat implementation.
We used the python API, and the insights shared in this blog post are based on it, however Azure offers APIs in several languages so you may use your preferred one.
A bit about the architecture
The Solid solution works by first building a knowledge layer representing the organization’s data stack, including tables, columns, BI reports/dashboards, SQL queries, and more. These data assets can be represented by structured elements, having different parameters based on asset type. In addition, our data also includes unstructured text documents, like internal documentation of analyst teams, general information about the company, and such. (more on that in a future blog post)
We take that enriched knowledge layer and populate a RAG with it.
When a user asks a question in our chat, that RAG is searched by the Azure AI Search service to retrieve relevant data assets, and a response is generated using Azure OpenAI (GPT).
The knobs and levers we played with
There are many parameters exposed by the Azure AI services. The ones we found most useful for our use case are:
GPT-related parameters:
Model choice – which OpenAI LLM model to use (see this list of options) - we used GPT 4o and GPT 4o-mini, depending on the use case. GPT-4o is usually more accurate but slower than GPT 4o-mini.
Temperature & Top_p - LLM basic parameters. We used temperature between 0 and 0.3, and top_p between 0.3 and 0.5, depending on the level of creativity we wanted and whether we wanted ChatGPT to use its own knowledge vs. our need for it to stick to the information retrieved from the RAG.
Seed - According to Azure, setting a seed will make the system generate consistent results. That is, sending the same user request over and over again will return identical results. We set this parameter, as defined in their guide, and although results were a bit more stable it didn't guarantee consistent results, and we kept getting very different answers.
Stream - while many AI chat experiences have a nice streaming experience, and you can turn this one within the Azure service, we decided to have it off. We did this because we had to make some changes in the response before showing it to the user (this includes adding links to Solid asset pages and some formatting/styling improvements).
Response_format - this parameter defines how the LLM response will be structured. You can pick between free text or JSON. Although having a response in JSON could have been great for our reformatting needs, we ended up asking for free text only because when asking for a JSON format we frequently got an invalid JSON structure that couldn’t be processed.
Search-related parameters:
Query_type - This parameter defines the search method to be used, which can be a plain text search, a vector search, a semantic search, or a combination of those. We used the “vector_simple_hybrid” method which generates a single relevance score based on an aggregation of text similarity and vector similarity calculation.
Embedding_dependency - An embedding is a numeric vector representing the contents of an entry in the RAG, that is used in vectorized search. This parameter defines which embedding algorithm to use to convert the user’s request to a vectorized representation to search the RAG. The algorithm selected here must be identical to the one used to generate the RAG’s document embeddings.
Top_n_documents - the number of documents to retrieve. This depends on the use case you want to solve. For example, we chose to retrieve 10 documents and let GPT choose between 1 to 3 options to be represented to the user.
Strictness - a rough threshold on document similarity, used to filter our irrelevant documents. This parameter ranges between 1 and 5, where the default is 3. In our case, the accuracy of each retrieved result is very important, and therefore we set this parameter to 4 which is more strict than the default.
In_scope - defines whether the LLM should use only the provided documents (True) to generate an answer, or can also use external knowledge to enrich the response (False). We used “False” to enable the usage of external knowledge as well.
Challenges we came across
Using Azure AI provided us with valuable experience, but we also faced some challenges:
Inconsistent Responses: we experienced major inconsistencies all along the way, no matter how we set the seed, temperature, and top_p parameters. It wasn’t clear if these inconsistencies were due to internal query handling processes or were caused by the randomness of the language model itself. We used diagnostic logs of Azure AI search, trying to get some insights on how this black box works, but the logs provided very limited information.
No way to filter data for search: Azure AI search provides advanced filtering methods. However, these capabilities are not exposed in the API of the discussed service. Therefore, each search was executed over the entire RAG, and we couldn’t direct the search to a specific asset type (for example, based on the user type or the specific user flow in our system). This lack of control made it harder to deliver precise results in a given context.
Only one RAG: the API Azure provides for this service limits the use of only one RAG instance. Having different kinds of data assets, which are not all in the same structure or with the same relevance, we sometimes prefer to represent the data in different RAG instances, however, this is not supported by this API.
Lack of Control of Search Logic: examining the diagnostic logs mentioned above, we discovered that for each user request this service auto-generates 3 different search queries that are then used to search the RAG. The API provides no controls over this process and for us it wasn’t clear how these queries are generated, what is the difference between them, and how the results returned from the different searches being combined into the LLM prompt that is used to generate the final response.
Inability To Layer On More Parameters: Solid’s algorithms evolved, and we wanted to include more logic and methods in the search - such as using different scoring functions and field weights based on asset type (taking into consideration asset popularity or specific customer preferences) - however the API doesn’t support these advanced capabilities.
Why Change?
While Azure helped us get started, our growing needs showed that we needed more control and flexibility. Specifically:
Custom Search Logic: We wanted to define our own rules for searches, filters, weights, and result ranking—things we couldn’t do while using Azure’s black-box API.
Structured Responses: To improve user experience, we needed responses in a consistent format like JSON, which this API struggled to deliver reliably.
Adding agents: The next steps of the experience we want to generate require the development of sophisticated agents who will work together to handle a large number of complicated use cases such as SQL generation and analysis task completion.
Better Data Organization: We want to be able to test and compare other data handling options, including splitting assets to different RAGs to enable custom representations (e.g., tables vs. metrics or structured elements vs. unstructured text), or using RAG platforms other than Azure AI Search.
What We’re Doing Now
We decided it was time to “break” the black box and build a new chat framework ourselves to address these advanced needs. The new architecture enables us to do a few important things we couldn’t do before:
Custom Query Pipelines: We’re creating our logic to filter, rank, and refine search results based on user needs. This allows us to add more elements to be considered in the search - such as the popularity of an asset or the relevance based on the user's role, seniority, and organizational affiliation.
Accurate data representation: Splitting data into multiple RAGs ensures each type is handled in the best way since we’re no longer limited to representing all elements in the same data structure.
Improved Chat Flow: We’re now able to control each step of the flow, allowing us to support different logics per use case, do extra-validation of the output at each stage, or send it back for enhancement when needed. We are deploying advanced agents within the flow to facilitate this.
Testing Alternatives: We’re exploring other RAG tools and LLM services to find the best fit for our platform, potentially outside Azure’s offerings.
Takeaways for Others
Azure’s solutions are great for teams starting with RAG or AI-based chat. As your needs grow, you might find the lack of control limiting. For us, it was a good start, but taking charge of the architecture ensures we can deliver better results for analysts, increasing accuracy and consistency.
We’ll keep sharing updates as we refine our system. By focusing on flexibility and user needs, we’re building a platform that truly helps analysts make a bigger impact with data.
 | A guest post by
|