
Testing Solid's chat: how we do evals - part one
With the increase in development of GenAI functionality within SaaS products, the need to do evals has grown in prominence. Maya, our VP of Research, Oren Matar, DS on her team, share how we do it.


For those who don’t know what Solid does, here’s a quick background: Solid is an AI-powered platform used by business users and analysts to shorten time to insight. Solid achieves this by helping business users find the dashboards/reports they need, communicate their requirements to analysts, and help analysts do their work much faster.
At the core of all of this is a “chat” engine, which is really much, much, more complicated than just a chat. We started with something very simple, then we evolved to a multi-stage chain, we even invested heavily in optimizing our RAG. What's particularly exciting right now is our work on a multi-agent platform, and I'll be sure to share more updates on that in upcoming blog posts. It’s an on-going journey, one we’ve never been on before. Truly exciting. (subscribe below to follow it)
Like any good software product, you must test this engine. In the world of AI, the concept of Evals is now prevalent. Started as a simple idea by OpenAI, evals are now critical to reliably deliver software in the world of AI.
What are we looking to evaluate?
The Solid platform does a lot of search, quite a bit of understanding of the user’s business needs (and the organization’s semantics), and a ton of answer generation. So naturally, we are looking to focus on:
The quality of the search results.
The ability to understand the business context.
The generation of answers.
We are looking to test every time something changes (code, model, etc.), as well as on-going in production (to identify deviations in behavior that are not intentional).
What makes things somewhat more complicated is the fact that users consume the intelligence of Solid through multiple interfaces - our web UI, our Slack bot, our JIRA integration, Chrome Extension, etc. Of course, it’s all available via API, so you test that, but there is a difference with how we treat a chat message that comes from the web UI vs the details of a ticket in JIRA.
To truly understand and interact with our customers' data, we've had to delve deep into the nuances of various asset types. For instance, the very definition of a "data asset" carries different implications depending on its context – the properties of an asset in a database table are not the same as those of an asset defined by a SQL query. This complexity is amplified by the fact that our customers utilize diverse datasets across different warehouses and BI platforms. Consequently, an asset on one platform can look and behave quite differently on another; consider how a dashboard in Looker, with its specific functionalities, differs in its properties from a dashboard in Tableau.you

Benchmarking
Before you can evaluate your progress/improvement/decline on something, you need a benchmark. To do that, we’ve used two main sources:
The actual chat messages / input from our users (per dataset).
Synthetic tests - we use AI to read the dataset and generate chat messages that it thinks users would write to find/use specific assets (see image above).
Both sources have challenges.
The user chat messages are quite varied. Some users treat our system like Google search and will only type in a few words. Others will type full sentences, even saying “please” 4% of the time. Then some users don’t quite know what to type into the chat box and will have a wide range of inputs. Ensuring we provide the right answer to these varied queries presents its significant hurdle. Our customers' datasets often contain many similar items – for example, multiple dashboards that calculate revenue in different ways and with different filters. Determining which of these is the most appropriate for a specific user's needs often requires nuanced domain knowledge that only people within that organization possess. Of course, we allow users to thumbs up/down when they work with the system, so that helps us decide what to feed the evals engine, but users rarely click on those.
The challenge with synthetic tests is that they don’t mimic users well enough. As much as you try to get AI to behave like a user, it still feels the need to form complete sentences, with high levels of specificity, good grammar and punctuation, all following very predictable grammatical patterns.
To address this, we found a few techniques particularly effective:
Feeding the AI with examples of original user chat messages, so it can take a cue from how real humans do it.
Based on user research, we prompt the AI to generate distinct categories of messages—such as analytical and exploratory questions—each supported with clear definitions and real-world examples
Generating and sampling multiple variations: When prompted for a single message, the AI often falls into predictable patterns. Asking for many variations and sampling from them encourages greater diversity and unpredictability.
Finally, we take the synthetic messages and ask another AI to rephrase them using different grammatical structures and vocabulary.
Another issue with synthetic tests is that while we look at an asset, generate synthetic tests for it, and run them through the engine, it’s possible that there is a better asset that answers the same question. For example, imagine we see an asset for “User Churn Reasons”, and the question we generate is “Where can I find user churn stats?”. It’s possible there’s an asset for “User Churn - Yearly Tracker” that is a better result for that question.
Metrics we measure in our evals
You can only improve something if you’re clear on how you measure it. For the purpose of our evals, we’ve defined the following metrics:
Accuracy - are we recalling the right assets?
Consistency - if you try the same prompt 10 times, do you get the same result 10 times? What if you try with a question that’s only slightly different?
Retrieval time - users have a bit more patience to wait for AI (vs Google search), but not a huge amount.
Cost - we live in a capitalistic world after all.
Scale - quite obvious.
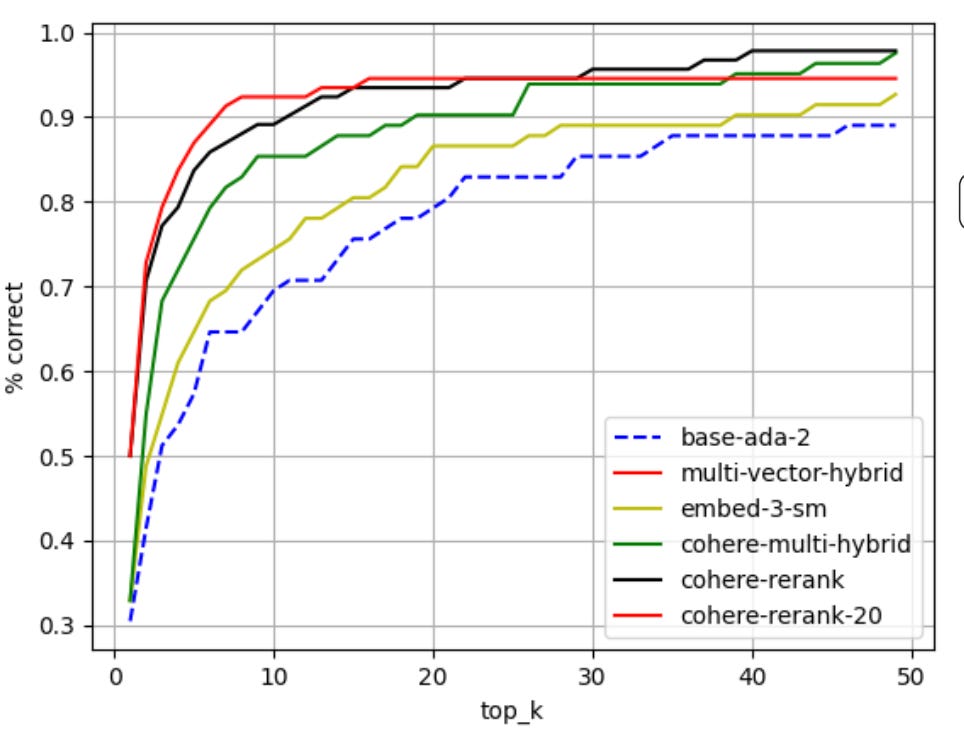
For example, this graph measures accuracy, and the engine’s ability to provide the right response within the first couple of options it shows the user (each option represents a different combination of embedding algorithm and reranker algorithm):
Next steps…
So once we’ve established the benchmarks, we test across permutations - try different models, prompts, embeddings, vector DBs and so forth. It’s a very systematic, and scientific, way of evaluating options for improving the accuracy and reliability of our engine.
In future blog posts we’ll share details of our Search Evaluation System (home-grown tool for testing changes), the metrics we track, and so forth.
Interested in learning more about Solid, or how it works? Hit us up.
 | A guest post by
|