
From Black Box to Best-of-Breed: Our RAG Optimization Journey
As we continue to "break the black box", Tal Segalov, Solid's CTO and Co-Founder, walks us through the improvement on the RAG/search side.

Ever feel like you're wrestling with a black box? We certainly did. When we first implemented Retrieval-Augmented Generation (RAG) to search across our customers' complex data stacks – think schemas, tables, queries, BI dashboards, DBT models, the whole shebang – we opted for a simple, all-in-one solution to get started quickly. We picked Azure AI Search. It felt like the easy path.
But, as perhaps expected, "easy" didn't mean "effective," especially when dealing with tens of thousands of distinct data objects. Our initial RAG setup struggled. Accuracy was hovering around 60% for finding the right answer in the top 5 results (people don’t generally read beyond the first few results), and consistency was also problematic - different wordings of the same question could get different results quite often. We knew we needed to roll up our sleeves and peek inside that black box.
Our journey started, as many do in the AI space, with embeddings. We benchmarked the usual suspects: OpenAI's ada-2 and embed-3-small, alongside Cohere's v4 embed. Just switching up the embeddings gave us a nudge in the right direction, bumping our top-5 accuracy to 70%. A decent start, but not where we needed to be.
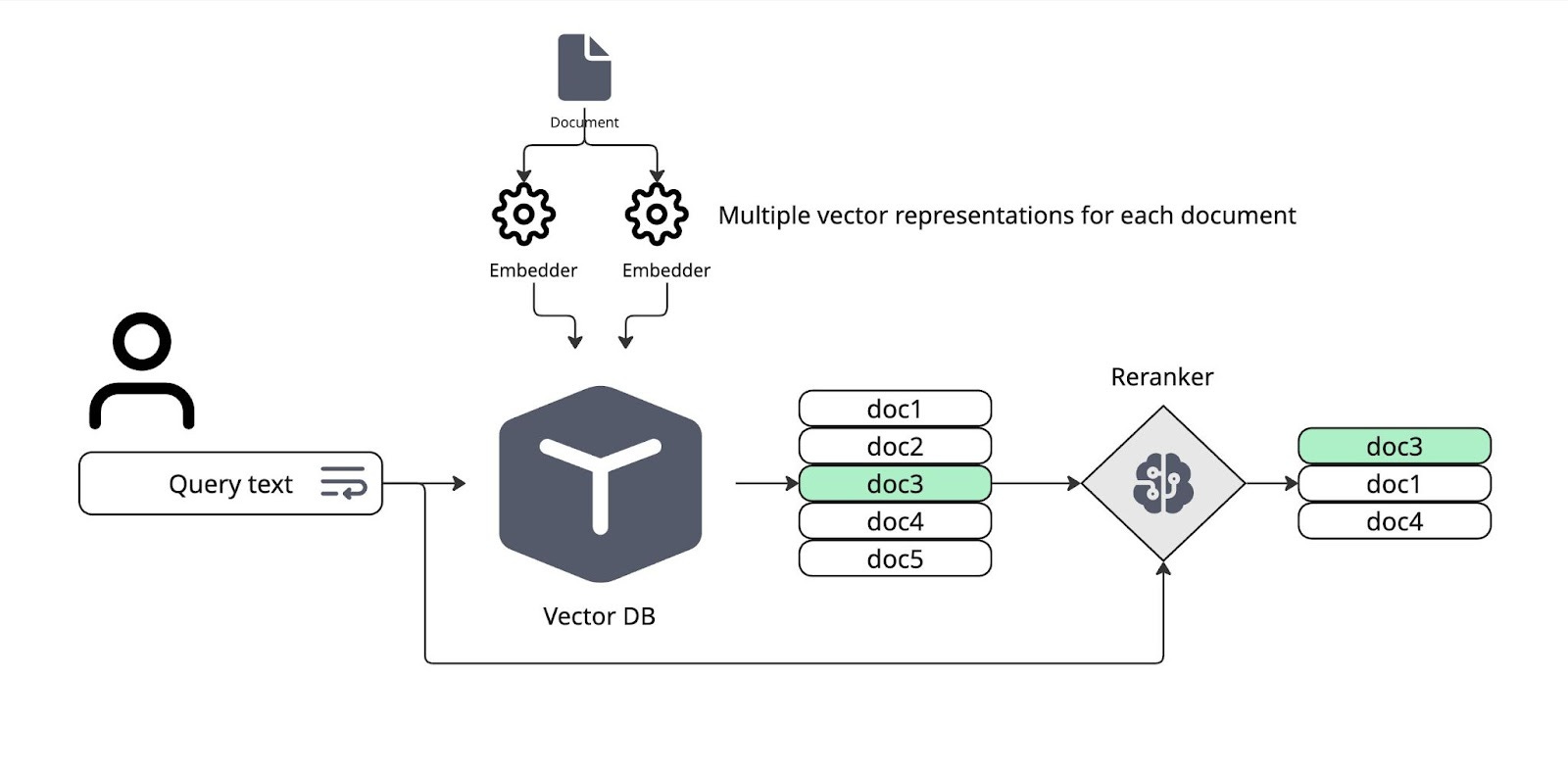
Best practice in RAG search is to have a two stage search where the first stage is a rough filter that uses vector similarity to find decent candidates for the search results, and then the second stage is a Reranker that takes these results and decides based on their actual content which are the best documents to answer the query.
Next, we added a hybrid search model in our VectorDB - instead of relying solely on the embedding vectors, hybrid search adds keyword-like search capabilities to find unique words that match between query and documents. We introduced a hybrid search approach, combining the classic BM25 algorithm with our embedding vectors. At the same time, we experimented with creating multiple vector embeddings for different parts of our object descriptions, capturing more nuances. This hybrid, multi-vector strategy proved fruitful, pushing us up to 80% accuracy. Getting warmer!
Then came the infrastructure question: the Vector DB. We tested several options. Interestingly, but perhaps not surprisingly, the choice of DB didn't really change the accuracy of the results – they mostly perform the same math, after all. However, the differences in performance and cost were significant! We landed on Qdrant. Being largely open-source made it cost-effective, and it integrated smoothly with our Azure environment.
The final piece of the puzzle was adding a reranker. This layer takes the top results from the vector search and re-orders them using a more sophisticated model, aiming to push the best answer right to the top. We tested a few, both open and closed source, and found Cohere's V3.5 reranker performed best on our specific dataset. This piece pushed our top-5 accuracy to an impressive 90%!
Here's a look at how each step contributed:
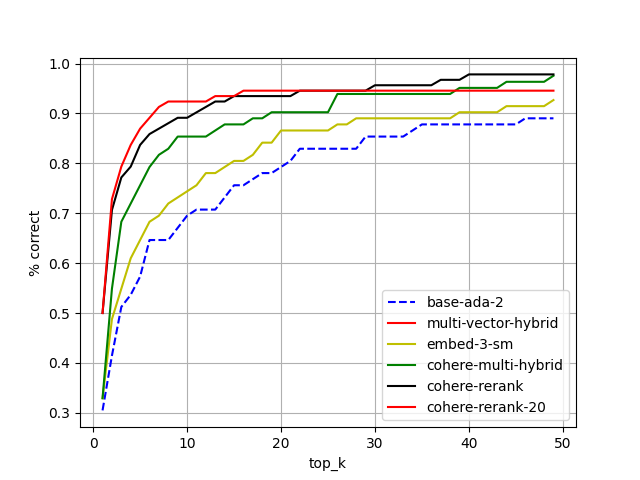
Step-by-step improvement in top-k accuracy as we refined our RAG pipeline.
So, what's the big takeaway from our RAG adventure? Don't settle for the black box if you need serious performance. Breaking down the RAG pipeline into its core components – embeddings, retrieval strategy, vector database, reranking – and rigorously benchmarking options on your own data is key. Choosing the best-of-breed for each component allowed us to build a system that truly meets the complex needs of searching enterprise data stacks. It takes more effort upfront, but the payoff in accuracy and reliability is undeniable.