
When users don't chat with your chat: solutions to help AI help people (Part One)
Maya and Oren, Solid's VP of Research and Senior Data Scientist, take us through what Solid does to help users give it the information it needs to help the user be more successful.


Most users aren’t yet “trained” on how to help AI help them. It’s what we call the curse of the white box.
The median prompt a user gives Solid is 10 words long. The average is 12. Half of those words are things like “a”, “can” and “what”. So in reality, there are about 5 words, per prompt, that our AI can make meaningful use of (“what” is helpful, but only to a limited extent).
5 words is not a lot to go by. We wouldn’t consider 5 words to be “chatting” with AI. That’s more like a search query.
So what can we (Solid) do to help users use the platform better?
There are two main paths - the first is the user interface itself; giving the user more hints and buttons to give us more information. We’ll cover that in a separate post.
The second path, which we will cover here, is building more intelligence into the AI (see what we did there?):
We provide the AI with a full glossary - all the terms the users within a given company are likely to use. Whether they are publicly known ones (ARR, HIPAA, FOB), or ones that are private to the organization (FHS, TRA, etc).
We also provide it with the full context of the analytical work that was done, and any recent work on the data engineering side. These JIRA tickets, Slack messages, etc, are very useful for the AI to understand what is going on.
Of course, it also gets a full inventory of all the assets we found, tables, queries, dashboards etc, with their deep documentation and quality analysis.
All of the above is really, really, useful to make the AI smarter. Our experience, though, is that it’s not enough. Today, we’ll dig into what we recently did to take things a step further. We’re sharing here with the hopes that it interests you, and helps other developers building their own GenAI-based solutions.
Pre-search clarification
When a user types a prompt into our chat, it goes through a whole series of stages (we described some of it before). One of those stages is where we search for assets that can help provide a response to the user. This is your typical RAG search, but with a lot of enhancements we’ve made to make it more precise and relevant.
The quality of input into the RAG search is key to making the search successful. Taking the original five words provided by the user and just using them as the search query is going to give us pretty bad results.
So, we expand the search considerably. We take the glossary we know, the business context and any other pieces of information we can draw on to expand the search query to something that will provide much better results.
Usually, that helps enough to provide a great result.
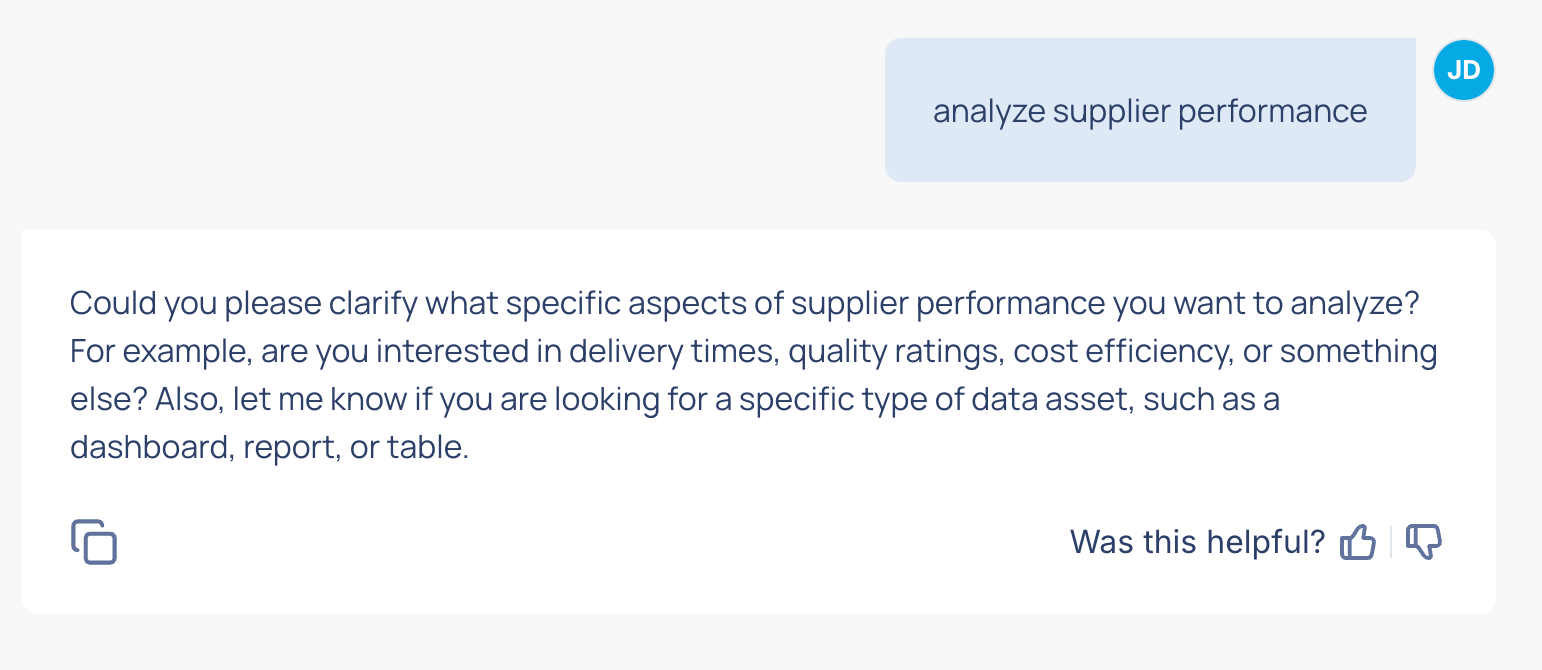
Unfortunately, sometimes, we don’t have enough information to be successful there. For example - is the user looking for a dashboard, or a query? If they are looking to analyze supplier performance, what metric are they looking to focus on?
So, our pre-search step here, is one where we use an LLM to go through the user’s prompt, and the other information we have, and determine if we have a good enough query for our RAG search to provide high quality results. If we don’t, we quickly respond back to the user, asking for more information:
Post-search clarification
Sometimes the prompt is pretty good, and it gets through the pre-search validation with high marks. Then, we go and run the RAG search and come back with a list of items. As part of our search, we use a reranker to determine what are the assets that are most relevant for this search. The re-ranker provides a score of 0.0 to 1.0 for every asset.
Sometimes, we get a list of assets that are very close to one another in terms of rank - 0.91, 0.90, 0.912, 0.89. This means that they are all good assets for the query, but the list is too long to use as a response for the user. (our experience shows that users don’t like a long list of assets to dig through)
We call this “ambiguity”, and have very specific mathematical definitions to identify these cases.
When ambiguity happens, we take the list of high-score assets, and compare them to one another. We look at the metadata of each asset (what filters and specific dimensions are available, what is the time or location granularity, who usually uses this asset, etc.) and look for what’s different. We do this at two levels:
The metadata we’ve collected about the assets previously (before this specific chat instance).
A live, LLM-assisted, comparison of the assets based on how they look at the moment. Imagine a user would need to compare the assets if we were to present the list to them… so we’re letting the AI take a stab at it first.
To give a grossly oversimplified example - let’s say the high-score asset list includes a table about the churn of product A, and another table with the churn of product B. The difference is that the first is about product A, and the second product B. The rest is similar.
We do that for all the assets in the top of the list, and get a list of differences. We then use this list to generate follow up questions. In the above example, we generate a question “Are you looking for churn in Product A or Product B?” (multiple choice answer is provided).
By following this approach, we generate multiple such questions for the user. For example:
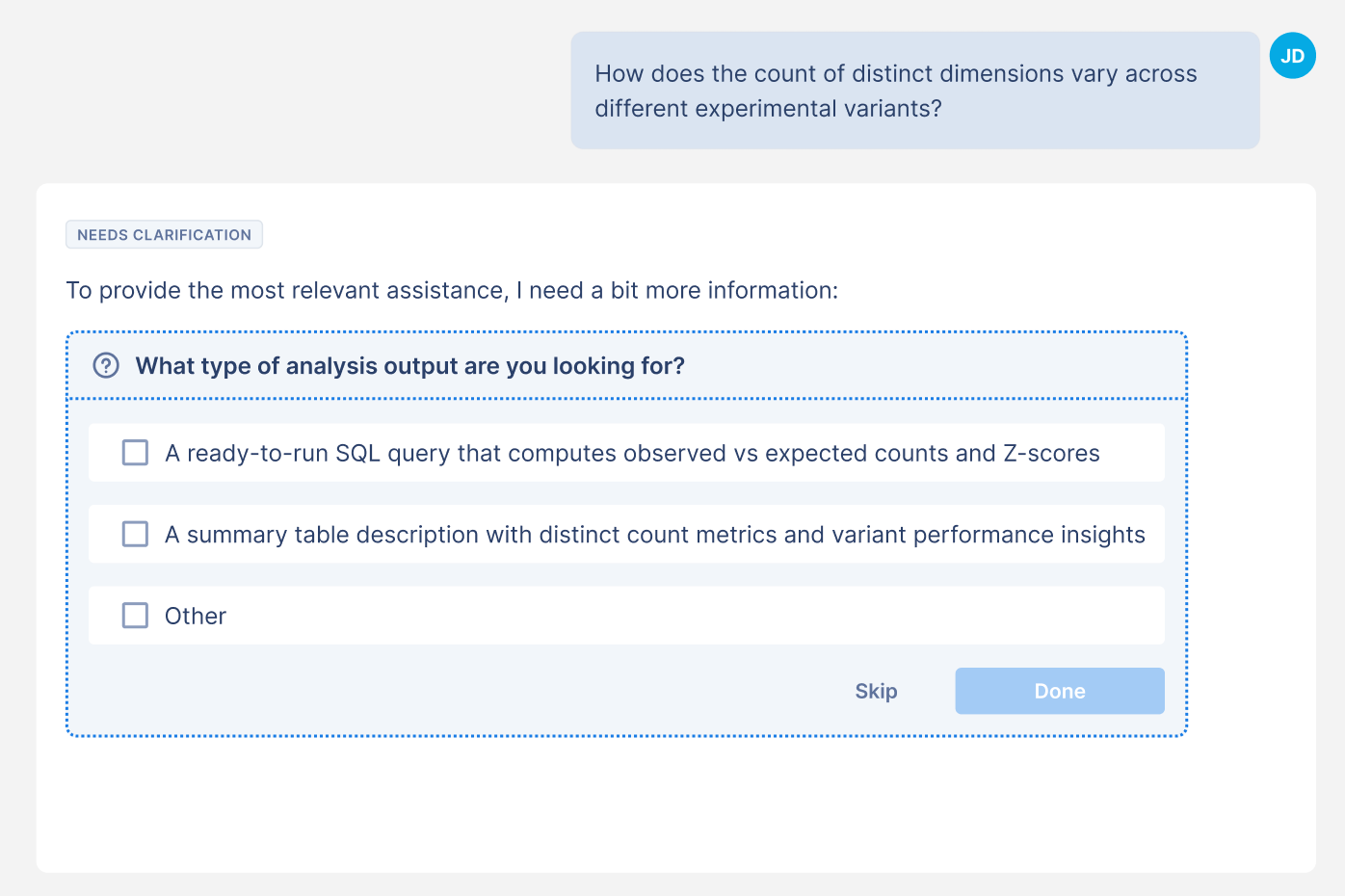
For this user prompt: How does the count of distinct dimensions vary across different experimental variants?
We will generate these questions:
Which experimental dataset are you interested in analyzing? (and list several datasets we found)
What type of analysis output are you looking for? (and let the user choose between a few methods of analysis)
What time scope do you prefer for your analysis? (and offer choices like “latest date snapshot (pre-aggregated data)” and “historical and time-series analysis”)
Once the user makes their selections (or doesn’t… users can skip and simply provide some other information they’d like), we continue with our search and preparation of an answer to the user:
Summary
While users around the world are still learning to use AI for their day-to-day, it is the application providers who must figure out how to help the users help themselves. Through smart user interfaces, intelligent responses from the AI and other mechanisms, we (the software vendors) need to be creative to make our users successful.
In this blog, we share many other similar learnings. You’re always encouraged to subscribe and get our latest: