
How the Solid chat works
Maya Bercovitch, Solid's VP of Research, sheds light on the evolution of Solid's chat from a simple Azure implementation to a multi staged complex flow.

When you first build a software product, you start with basic demos or prototypes. You show a design in Figma, or build some rapid prototypes that are meant to simulate the user interaction (and today, it’s even easier to do thanks to Lovable, Bolt and Base44). Once you’ve validated the flow that will appeal to users, you build your first fully functioning application.
In our case, we used Azure AI services to do so. It was great to start, but ended up being a black box with too many misbehaviors. We weren’t able to build a production-grade AI application using just those services. So we broke them apart and started investing in each stage separately (and together). In this blog post, I’ll share how the Solid chat is built now.
The requirements
The Solid platform is used by analysts and business stakeholders to find the analytics assets they need - dashboards, reports, tables, queries and so forth. The demand for quality is high - users repeatedly tell us that if a system gets the answers wrong multiple times in a row (or, doesn’t provide enough value), they’ll stop using it. Makes sense, of course.
In addition, the range of questions people will ask in the chat, and how they will ask those questions, is immensely large. When you put a white input box in front of a user, they will enter things you never imagined they would. Even if you give them guidance in the user interface - they will still write whatever is on their mind.
Speed is also a factor here. While people understand that the more time you give an AI to answer your question, the higher the quality, people are also used to the search experiences provided by Google and the like, that are largely instantaneous.
Balancing these requirements is extremely delicate. This is especially challenging in the world of AI, where developing software isn’t linear like it is in the normal SaaS world. In AI - models evolve rapidly and each with its own behaviors. To me, the behavior of AI feels like that of a child - mostly does what you ask it to, but sometimes goes very far off.
Quality in, quality out
The first and most important step in building an excellent chat service is developing a high quality RAG system, where relevant data is well-organized and documented.
The information in the RAG should be optimized for both search—enabling quick identification and retrieval of all relevant data—and for the LLM - ensuring it has everything needed to generate accurate and well-explained responses.
At Solid, we dedicate a significant portion of our time to optimizing the representation of our customers' data assets and business terminology. We continuously collect data from various sources, including BI systems, databases, and ticketing systems. Next, we standardize asset representation by type—such as creating a consistent format for database tables or queries. Finally, we enrich these assets with relevant business context and detailed descriptions, ensuring they effectively capture their intended use and purpose.
The architecture of the Solid chat - behind the scenes
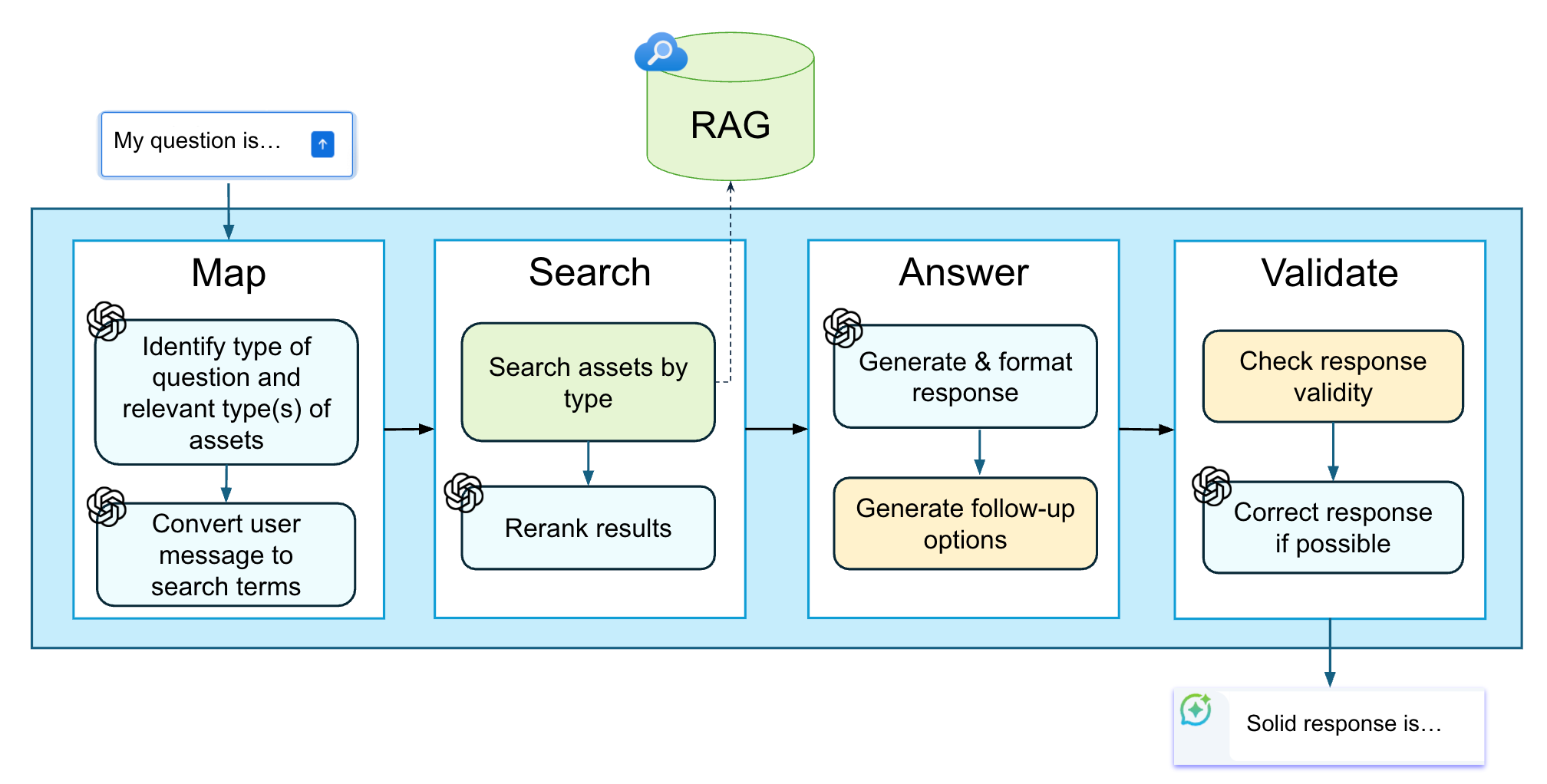
As we broke the black-box, and in order to meet the requirements, we set a four-stage flow for every chat session. When a user enters a question in the chat, what they see is the AI “thinking” for a few seconds, and a response provided. That response contains the highest-quality assets that Solid recommends using for the specific question.
Behind the scenes, there’s this four-stage flow:
Map - try to understand what the user is looking for. A dashboard? A table? A query? Maybe the definition of a metric? The answer is based both on the current user’s request and the characteristics of the user - are they a business stakeholder? Are they an analyst? What part of the org are they in?
For example - business stakeholders aren’t shown SQL queries in our chat.This classification will direct our RAG search, and informs the later stages of the process what the answer should look like.
In addition, at this phase, we “explode” the question into possible search terms. For example, consider that in your organization, you use an acronym called TAE. If you ask ChatGPT what TAE means, you’ll get various explanations, none of which match the meaning of TAE in your organization.
As part of our data-crunching processes, we build a glossary of the organization’s internal terms and load that into our RAG. When chatting with the user, we convert any terminology used by the user to the possible permutations of it (for example, converting TAE to Total Assets Evaluated and vice versa). This helps us search for assets that cover the user's needs, no matter how they call it.
By the way - if the user asks for something our chat is not meant to support, then at this point we let them know and instruct them what our chat is able to do.Search - we search our RAG (implemented as an Azure AI Search index) for relevant assets that should be used as part of our response. This is done using search terms and filters determined in the previous stage.
Ranking search results is a complex two-phase process. We begin by leveraging Azure’s hybrid search—a combination of text-based and vectorized search—along with Azure’s semantic search and boosting functions to generate a combined score based on:Asset relevance to the user’s current request,
Asset quality, evaluated using specific criteria for each asset type,
Asset popularity, and
Customer preference levels (for example, our users have indicated that certain database schemas are preferred by their analysts, as they are considered the source of truth—more reliable and clean).
This initial search typically produces a list of multiple assets. From there, we need to identify the one or two most accurate assets that best answer the user’s query. To achieve this, we leverage the latest reasoning capabilities of GPT to analyze the user’s intent and select the most relevant asset(s) that provide the needed information or guidance.
Answer - here we use another LLM to structure the response to the user. We try to stick to a rigid structure of responses to make it easier for the users to consume, as well as easier for us to validate (see the next step). The responses are generally structured into offering one or two options (the one/two best assets determined in the previous stage), with explanations on why we chose them.
If we couldn’t find an asset that fully matches the user’s need, but only partially, the response will explain the gap and, if possible, will provide guidance on what should be done to bridge the gap (for example, changes to be made in a query we retrieved to match the user’s time frame definition).
At this phase, we also automatically generate follow up questions. For example, if the user asked for a table that covers a specific topic, we will offer to show them SQL queries using that table as a follow up. This is meant to help users understand what questions they can ask of the chat (remember the “white box problem” I mentioned above).Validate - this is a crucial stage. As we mentioned, LLMs may invent things, or the search results might not be exactly what the user was hoping for. And, as we remember, quality is super-important here.
So at this point, we check the response’s validity - are all the assets the correct ones? Are they real, or did the LLM invent/hallucinate something (like a column that doesn’t exist)?
At this stage, if we find any issues, we send it back to the LLM to correct. In some cases, we will decide that, actually, we cannot provide a reliable answer to this question, and will respond accordingly.
This work is made quite a bit more interesting by the fact that there are so many models out there, and you can mix and match them. In addition, they evolve constantly. It’s a never-ending-chase for us to evaluate the models and pick the right ones for each stage in the flow. In another blog post, we’ll discuss how we test the models and make our decisions.
Parting thoughts
There’s a global rush now to build applications that leverage AI to accelerate business processes and improve their quality. At Solid, we focus on the analytics workflow, but we see similar challenges in many other product categories and businesses.
My hope is that by sharing our learnings, we are helping the broader industry. Just as we, at Solid, learn from others sharing their own experiences.
Any follow up questions? Feel free to comment below. 👇