
Your data agents need context. But context is not enough
Jason Cui and Jennifer Li from a16z are absolutely right to put context at the center of AI for data. Yoni Leitersdorf, Solid’s CEO & Co-Founder, shares Solid's perspective on the matter.

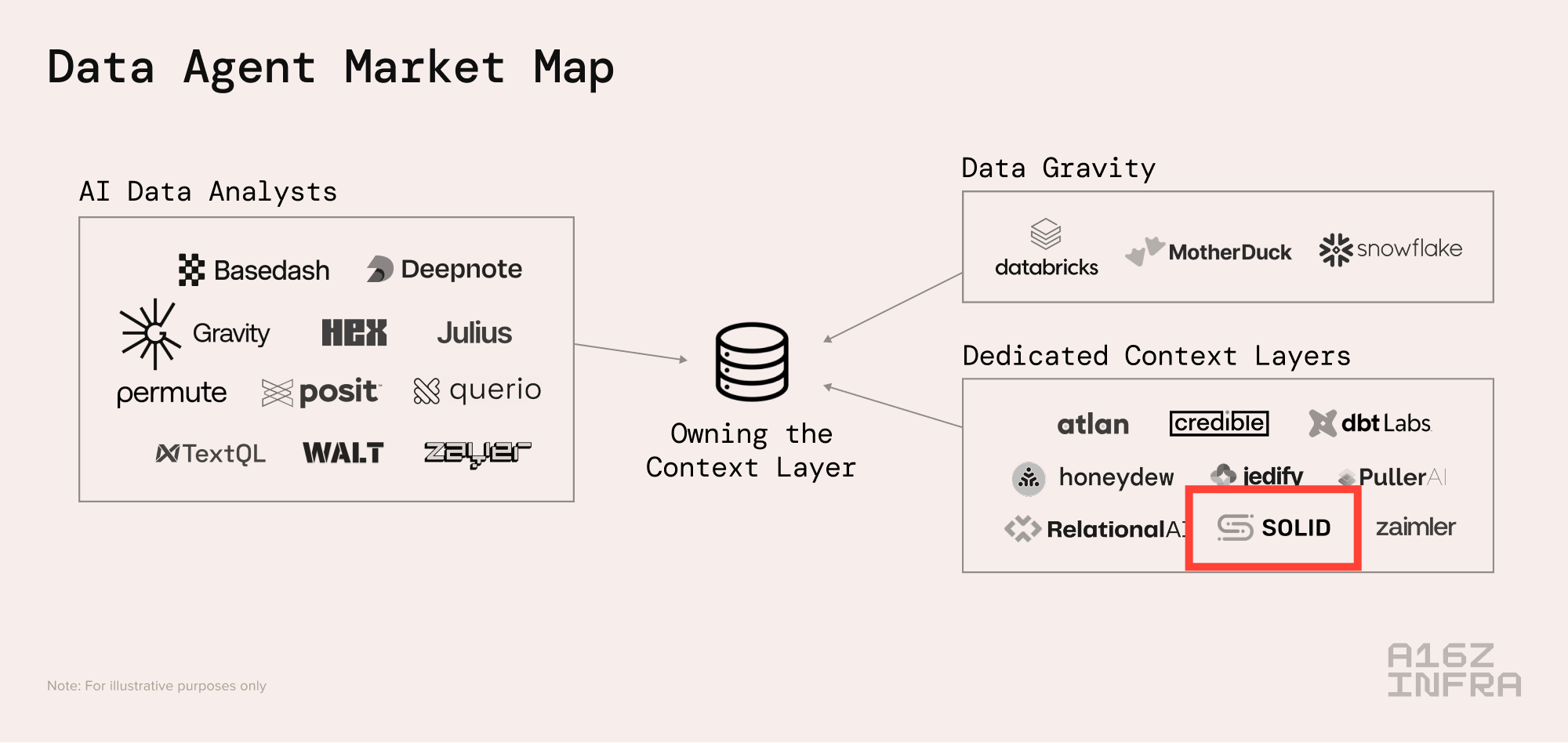
First, kudos to Jason Cui and Jennifer Li for their a16z post, Your Data Agents Need Context.
It’s a strong piece. More importantly, it puts the conversation in the right place.
A lot of the market still talks about data agents as if this is mainly a model problem. Better reasoning, better SQL generation, better interfaces, and suddenly everyone in the business can ask whatever they want and get back a trustworthy answer.
That’s not the main blocker.
Jason and Jennifer make the important point: the real blocker is context.
Not generic context. Real business context. Which definition of revenue is the right one. Which dashboard people actually trust. Which table is technically available, but should not be used. Which metric changed meaning last quarter. Which exception “everyone knows,” but no system has ever written down.
This is exactly why, in Data Chatbots: what people are really doing, I argued that enterprise data is not just a SQL problem. Every company has its own business language, and often multiple business languages. The model is not just translating English into SQL. It is trying to navigate an organization’s internal logic.
That is much harder.
Context is the problem. Static context is the trap
Where I’d push the a16z argument a step further is this:
Context is necessary. But static context is not enough.
Most enterprise context is messy. It lives across BI tools, dbt models, semantic layers, dashboards, documentation, tickets, query history, Slack threads, and people’s heads. Some of it is useful. Some of it is stale. Some of it conflicts with other pieces. Some of it was right six months ago and wrong today.
That’s why I keep coming back to a simple point: everyone’s data is messy. No one has perfect documentation. No one has a fully clean warehouse. No one has a beautifully maintained source-of-truth map that always reflects reality.
And that’s okay.
The mistake is thinking the answer is to pause everything and go build a pristine context layer by hand.
That sounds good in theory. In practice, it can turn into the next documentation project that starts with great intentions and slowly falls out of date. We’ve seen this before in catalogs, governance projects, and semantic initiatives. It’s also why I think Tal’s point in Semantic layer for AI: let’s not make the same mistakes we did with data catalogs is so important: if humans have to manually maintain every part of the system forever, the system usually loses.
So yes, agents need context.
But the bigger requirement is that context has to keep up with a real business. New product lines get added. Definitions shift. Dashboards become stale. Teams change how they operate. The “trusted” table from last year may no longer be the one finance relies on today.
If your context layer cannot adapt to that, it is not really a context layer. It is a snapshot.
Enterprises already have more context than they think
The good news is that companies are not starting from zero.
A lot of their context already exists inside the work they’ve done over the past decade. It’s embedded in BI, in semantic models, in modeling layers, in warehouse metadata, and in query patterns. It may not be organized perfectly, but it’s there.
That’s one reason I wrote Throwing away BI is a Bad Idea. There is this temptation right now to act as if AI will replace everything that came before it. I think that’s the wrong frame.
Your BI stack contains years of accumulated business logic. Your dashboards, LookML, dbt models, Power BI reports, Tableau workbooks, and saved queries all encode decisions the organization has already made. Not perfectly, of course. But they are still among the highest-signal assets you have.
The right move is not to discard those systems.
It’s to extract from them.
That’s also why posts like Autogeneration of a semantic layer - the key for AI/BI and Data, Meet Business: Why You Need JIT Semantic Models, Instead of a Static Semantic Layer resonate so much with what Jason and Jennifer are saying. The market does need context. But it needs context that can be built and refreshed from the assets companies already have, not just from a manual curation exercise.
My takeaway
So my takeaway from the a16z post is pretty simple:
They are absolutely right that data agents need context.
I’d just add that context also needs infrastructure. It needs a way to be generated, refined, corrected, and updated without depending on humans to keep every rule and every definition perfectly current by hand.
That is the harder challenge.
And that, in my opinion, is where the next real wave of value will be created.
The timing insight here is crucial but underexplored. Context isn't just about having the right data — it's about having it at the right granularity for the decision being made. A weekly revenue question needs different context depth than a real-time anomaly alert. Have you seen patterns in how successful data agent implementations handle this context scoping problem?