
Test Driven Semantic Models: the missing piece for AI analytics
Semantic models are being built backwards by people, and that's bad. Let's learn from software engineering and start from the tests.

The software world figured out a long time ago that you don’t build reliable systems by writing code, shipping it, and hoping it works. You define what “correct” means first, then build toward it. That is the core idea behind Test Driven Development: write the test, write the code, make the test pass, improve the code, repeat.
Semantic models need the same shift.
If semantic models are going to power AI agents, Solid’s Text2SQL, BI tools, Snowflake Cortex, Databricks Genie, Looker, dbt, and every other analytics interface, “I think this model is right” is not good enough. We need Test Driven Semantic Modeling. And this is one of the most important innovations we’re building into Solid.
Semantic models are becoming production software
Semantic layers used to be mostly about consistency. Define ARR once. Define active customer once. Make sure dashboards don’t contradict each other too badly. That is still important, but AI changes the stakes.
Now the semantic model is the thing standing between a business question and the SQL an AI system generates. If the model understands the business correctly, the AI has a chance. If it doesn’t, the AI confidently generates nonsense.
This is why everyone is suddenly talking about semantic models again. The AI needs business context. But there is a hard truth underneath all the excitement: creating the model is hard, testing it is harder, and maintaining it over time is brutal.
Generation helps, and we’ve written before about why autogeneration of a semantic layer is key for AI/BI. But generation alone is not enough. A generated model still needs to be validated.
The old way does not scale
Today, most semantic model work is painfully manual. A data team starts with warehouse tables, ambiguous columns, dashboard logic, dbt models, old SQL queries, and business definitions scattered across the company. Then they manually choose entities, define joins, write metrics, add descriptions, test a few questions, fix obvious issues, and ship.
Then production happens.
A user asks a question the model doesn’t understand. A column changes. A metric definition changes. The AI picks the wrong join path. The generated SQL returns the right-looking number for the wrong reason. Now the team has to debug everything manually.
This is not a scalable process. It is also not how we build serious software.
The TDD idea, translated to semantic models
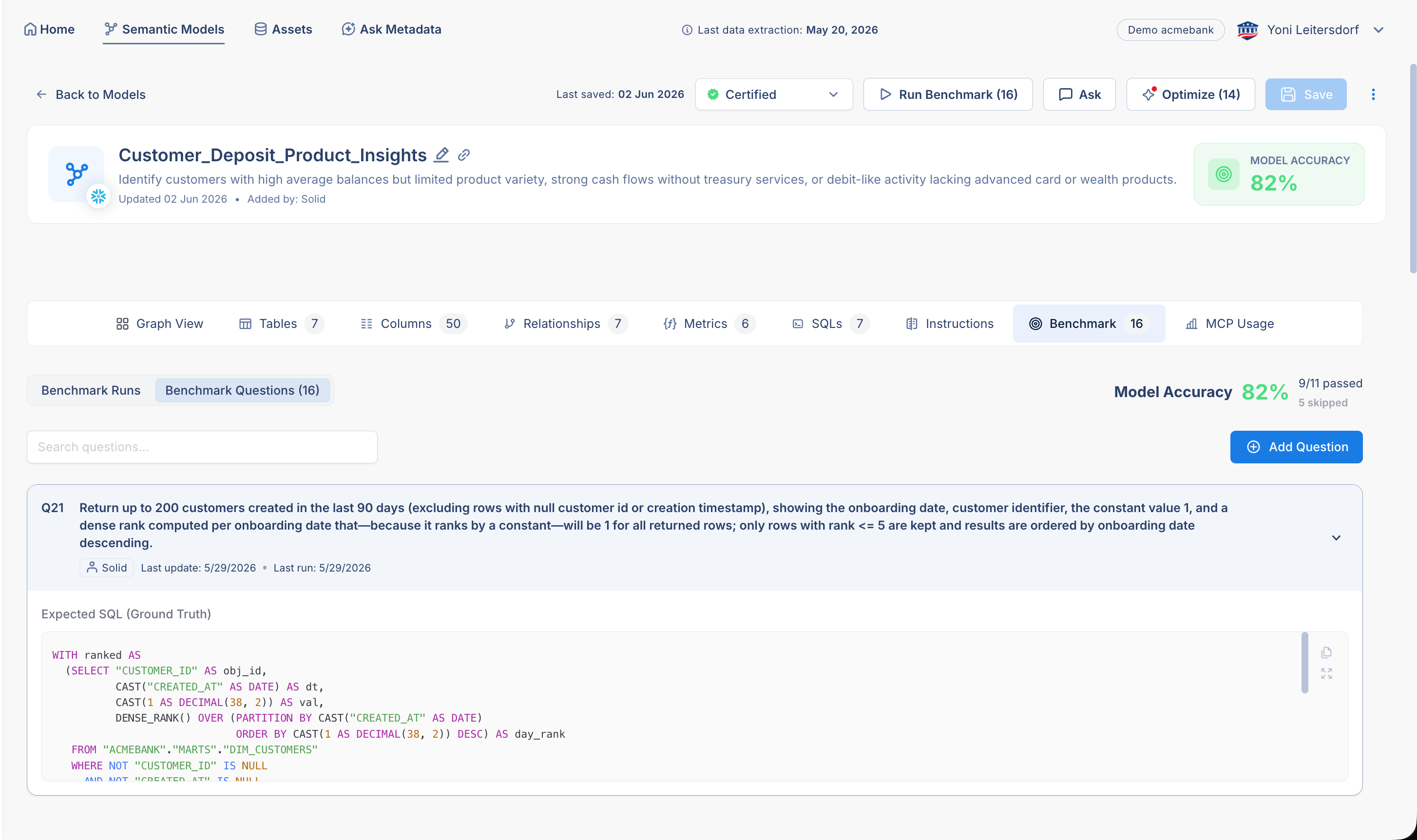
In software, a test defines expected behavior. For semantic models, the equivalent is a business question with expected SQL.
For example: “Which customers have high average daily balances but few open product types?”
That question is the test. The expected SQL is the ground truth. A semantic model passes only if the Text2SQL engine (such as Solid Analyze), using that model, generates SQL that returns the expected result and uses the right business logic.
That last part matters. It is not enough to accidentally return the same number. The SQL needs to use the right tables, joins, filters, and metric definitions. Otherwise, you don’t have correctness. You have luck.
This is what Solid Benchmarking does.
For every semantic model, Solid maintains a benchmark suite: business questions paired with expected SQL. These benchmarks can be generated automatically from historical SQL, added manually, imported in bulk, or promoted from real production questions asked through Solid’s MCP server. Solid then runs the questions, compares generated SQL to expected SQL, and shows what passed, what failed, and why.
That changes the workflow completely. Instead of building the model, hoping it works, finding out later, and fixing it manually, you get a loop: generate the model, run the benchmark, see what failed, apply fixes, run again, and save a better version.
That is red, green, refactor for semantic models.
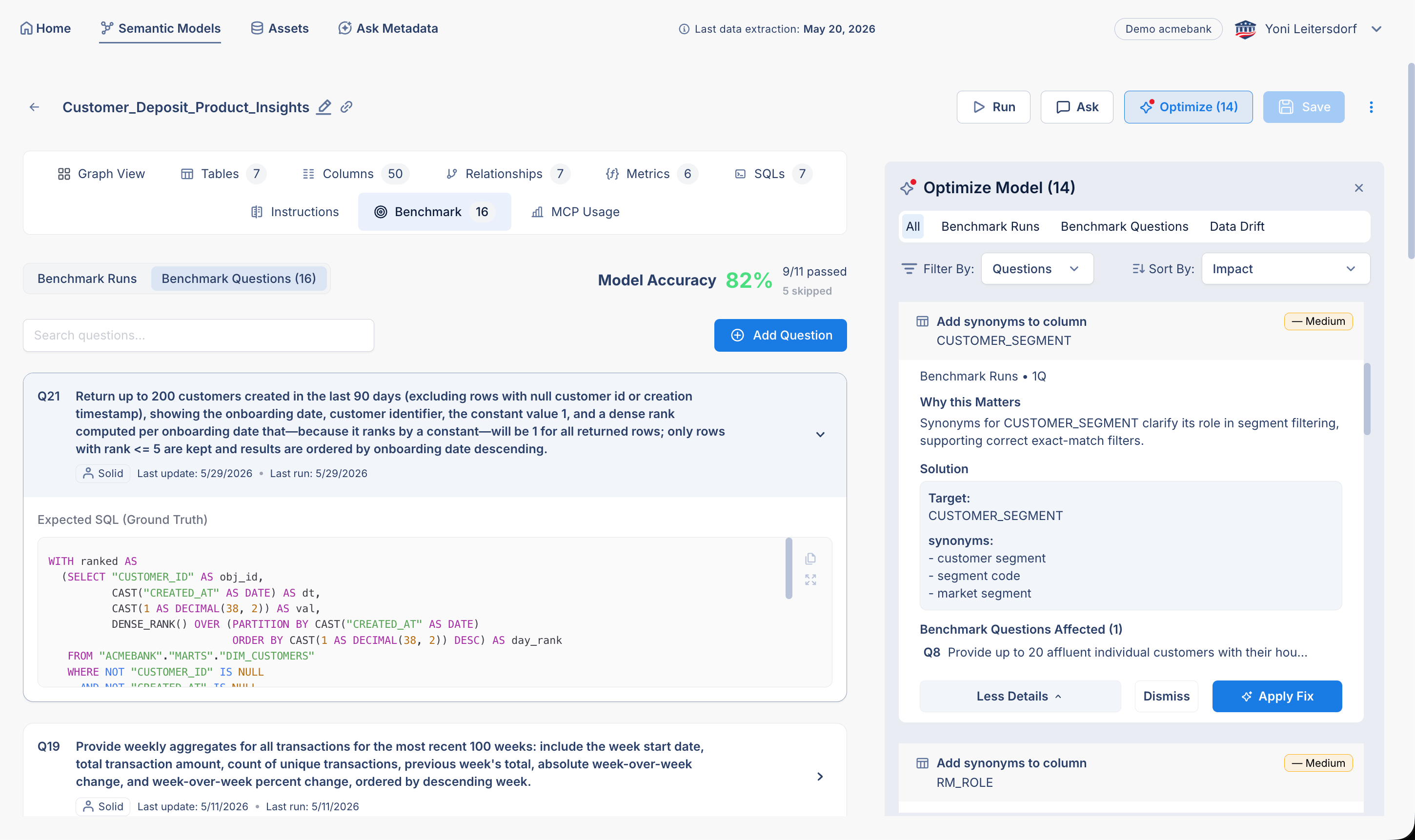
Optimize turns failures into fixes
A failing benchmark is useful, but only if it helps you improve the model. A question might fail because the model is missing a column, because the wrong join was selected, because a metric is ambiguous, or because the expected SQL is outdated.
This is where Solid’s Optimize capability matters.
Benchmark failures feed into Optimize. Solid analyzes the failures, identifies root causes, groups related issues, ranks them by impact, and recommends fixes. In most cases, the modeler can review and apply the fix with AI.
This turns semantic modeling into an operational loop, not a one-time project. You are not manually debugging generated SQL for hours. You are reviewing prioritized recommendations based on actual failures.
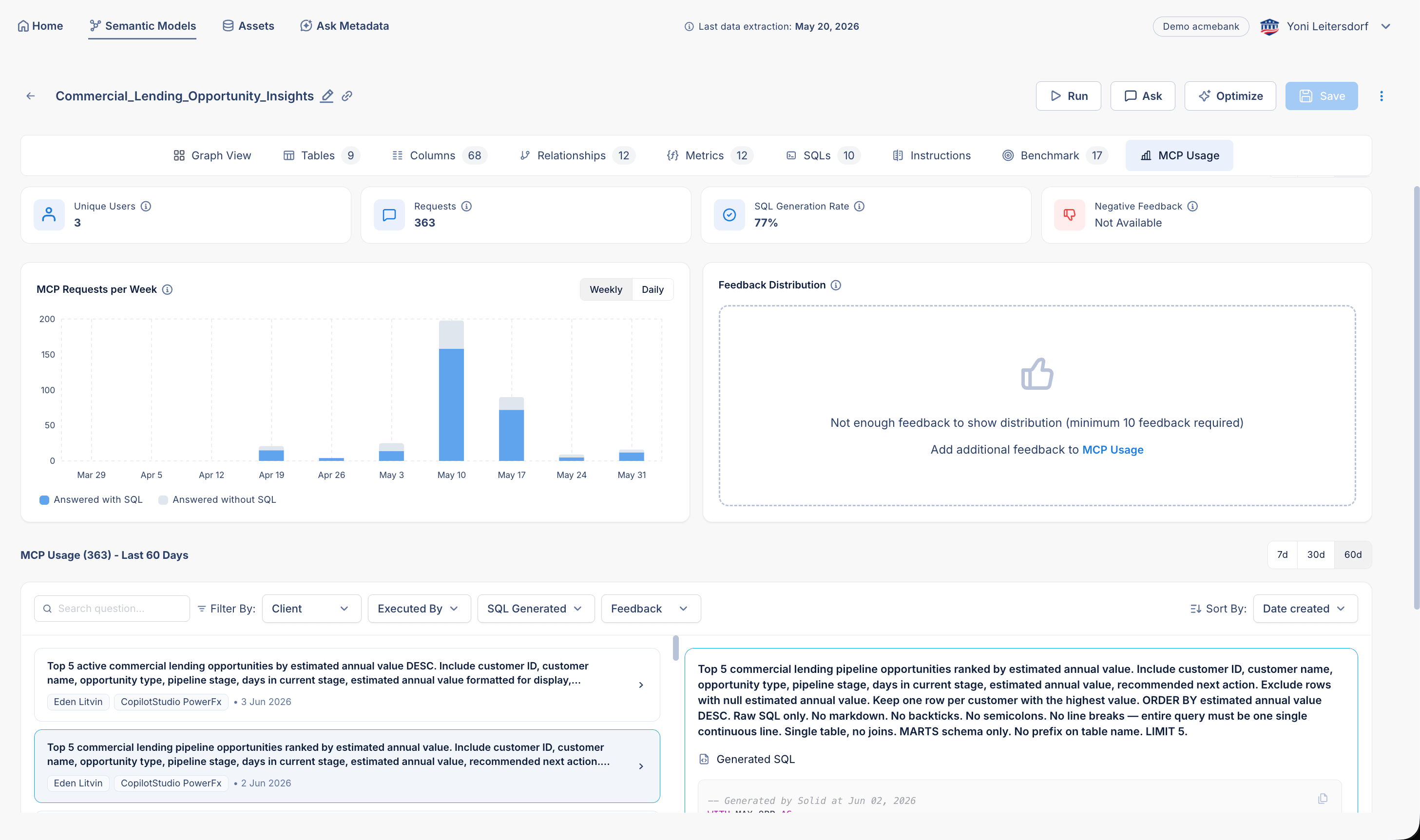
Production becomes part of the benchmark
The best test suite is not only based on what you thought users would ask. It also learns from what users actually ask.
This is why the MCP usage loop is so important. When an AI agent uses Solid’s MCP server to answer business questions, Solid shows the questions asked, the SQL generated, and the answers returned. A modeler can take a real production question and add it directly to the benchmark suite.
Production teaches the model. The benchmark suite remembers.
This is how semantic models improve over time instead of slowly becoming stale.
Versioning makes it safe
Optimization without versioning is scary. What if a fix improves one question and breaks five others? What if accuracy drops after a change? What if the model worked last week and nobody knows what changed?
Solid’s Versioning closes that gap.
Benchmark runs are tied to specific model versions. If accuracy improves, you know which change helped. If accuracy drops, you can see which version introduced the regression and restore the previous one.
That creates the safety net semantic models have been missing. Benchmarking tells you whether the model is correct. Optimize tells you how to improve it. Versioning lets you make changes without fear.
This is the real innovation
A lot of people focus on Solid’s ability to generate semantic models automatically. That makes sense. Seeing a model created in minutes is impressive.
But the deeper innovation is the lifecycle.
A semantic model is not a YAML file. It is not documentation. It is not a one-time artifact. It is production infrastructure. And production infrastructure needs tests, observability, optimization, versioning, and rollback.
Software engineering learned this lesson decades ago. Data teams should not have to relearn it the hard way.
The future of semantic modeling will look much more like modern software development: tests before trust, benchmarks before production, optimization based on failures, versioning for safety, and production feedback as fuel.
That is Test Driven Semantic Modeling.
And if AI analytics is going to move from impressive demos to trusted production systems, this is not a nice-to-have. It’s the foundation.
If you want to see this in action, contact us.