
Everyone wants Text2SQL, but the pros don't trust it
A weird light bulb went off in our minds recently as we've dug into Text2SQL in our customer conversations

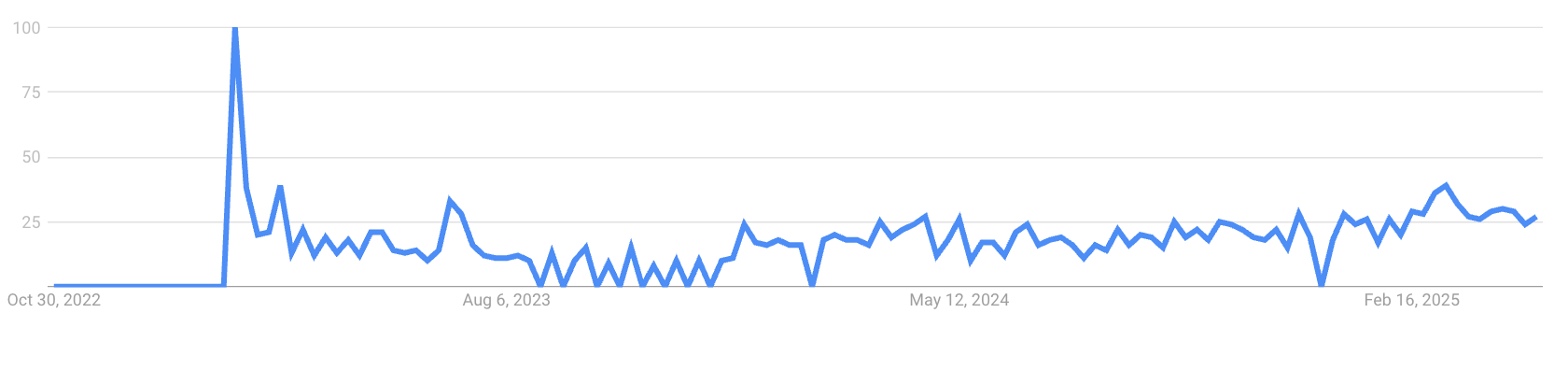
Shortly after ChatGPT was first announced in Nov 2022, we all realized that there could be a magical place where you write normal text, and AI writes SQL. The days of figuring out JOINs, complex sub-queries, and other shenanigans were behind us!
Boom - excitement went through the roof (see spike in the graph above).
Then, we all realized that hey… it’s actually way more complicated than you’d think. Apparently, the problem wasn’t writing JOINs, or using the right syntax. The problem is in understanding the data and the business context… what we’d all call the semantic model.
So… there was a lull (the period after August 2023 in the above graph). Going into 2024, there were some successes registered and it seemed like we were making headway.
Now, in the first half of 2025, we’re starting to see more and more reliable Text2SQL engines. These engines are highly reliant on a semantic documentation, and the vendors are making such capabilities available (if you’re willing to spend the time to write the documentation). So, are we getting to Text2SQL nirvana?
Houston, the pros don’t trust code that’s not theirs
Ugh… now we have a new problem apparently.
“Even if your Text2SQL engine is pretty good, it doesn’t mean that I’d trust the code it generates”, we’ve heard from an analytics team leader recently. His comment was repeated across conversations we’ve had with others.
It sort of makes sense actually. Those who have been in the technical field for a while, such as analysts, or software developers, are used to encountering someone else’s code and trying to decipher what it’s doing. Many times, at some point in this exercise, they will think to themselves “This is impossible to understand… I’d get my work done faster if I just wrote this from scratch, myself.” (and proceed to throw away the other person’s code)
Sounds familiar?
So, if AI is generating code for you, it doesn’t mean you’ll use it, because you might not trust it. I’ve been experiencing this myself even, as I’ve been using Cursor myself (don’t worry, I’m not writing any code actually used by our platform). Cursor has been amazing at completing many development tasks for me, but the code it generates is awful. Or at least I think it is.
Benn Stancil recently talked about this: “I’m reading the code it writes, I want that code to make sense to me and to be proximate to my abilities, and when it is not, it is bad code that needs to be fixed.”
It’s possible that the code the AI is generating is actually fine. It’s possible that it’s the best code ever. But… to me it looks terrible. It is I, the human, who doesn’t trust it.
Just like many people would rather ride a human driven car than a Waymo, because they don’t trust the machine (even though Waymo’s stats are wayyyy better), it seems like many people, especially the pros, don’t trust whatever AI is writing for them.
Which makes you think - if Text2SQL generates SQL and shows it to the user, then the human might not trust it.
But if Text2SQL generates SQL and runs it, and the human can’t see the SQL… will the human trust it more? Maybe not… maybe the human will still want to see the code (and we’re back to the same problem). But maybe some humans who would have not trusted the SQL code, will trust the output of the code, if they couldn’t see it?
Interesting thought…