
The Rise of the Expert SLM: Achieving GPT Performance with Specialized Open-Source Models
Smaller models are gaining attention, and can be very useful in specific tasks (especially considering time/cost/accuracy tradeoffs vs LLMs). Tomer Sidi, PhD, GenAI Researcher at Solid, explains.

There is a common misconception that “bigger is always better” in the world of LLMs. But when it comes to Text-to-SQL in production, we are discovering a more exciting reality: a specialized, fine-tuned “Small” Language Model (SLM) can actually outperform the giants.
In a live environment, Text-to-SQL isn’t a simple translation task - it’s an agentic system. It’s a dynamic loop of generation, execution, and self-correction. To push the boundaries of what our agent can do, we conducted a comparison between our current baseline and the Snowflake/Arctic-Text2SQL-R1-7B.
The results represent a significant achievement for specialized AI: the Snowflake/Arctic-small 7B model expert didn’t just keep up; it exceeded expectations and painted the road for database-finetuned models.
Agentic Framework for Text2SQL
The agentic workflow, partially illustrated in Figure 1, represents the end-to-end process for generating reliable SQL. The process starts with retrieving a semantic model that encapsulates the context of the question, i.e., the tables, columns, joins, metrics, and additional relevant data to answer the question. Then, with this context, an LLM based Initial SQL Generation Module (Figure 1a) creates the query that answers the question, which serves as the critical point of comparison between the GPT-based baseline and the Arctic SLM. Once the initial SQL is generated, a cycle of quality control and verification with automated checks assess the syntax, schema adherence, content and executability of the query, and attempts to fix the query if necessary (Figure 1b). The output of this process is a textual response including: the SQL query, the generation process explainability and detailed reasoning.
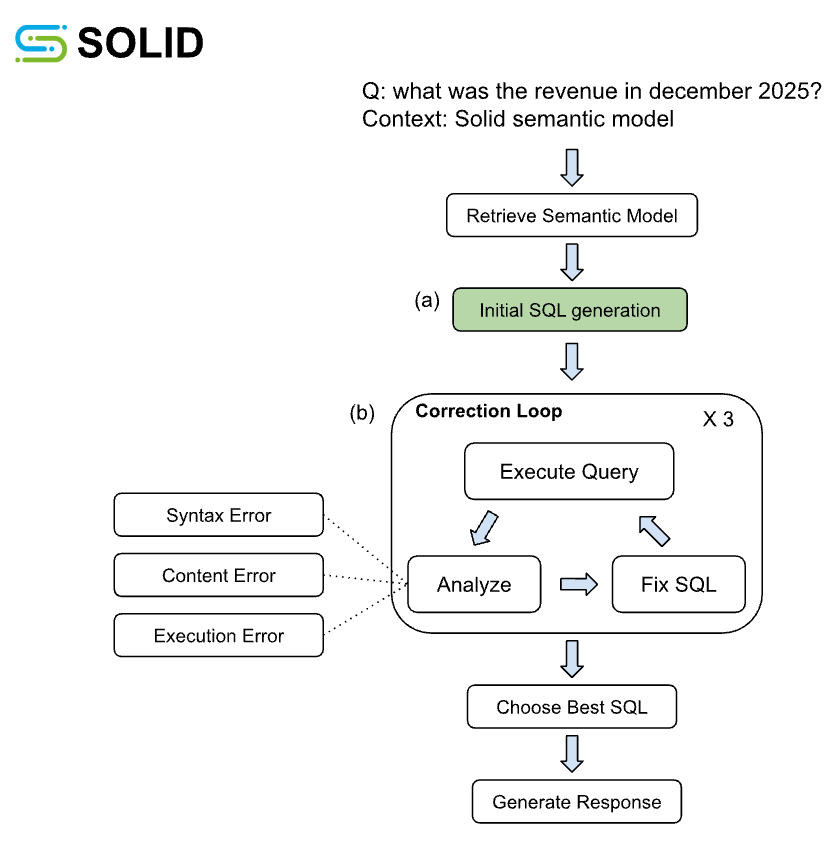
Building the Agentic Toolkit
Arctic-7B is a fine-tuned SLM specialized for generating SQLite queries given a semantic context. Incorporating it into a production agentic workflow requires controlling the information flow in and out of the model. Specifically, the prompt structure of the semantic context must be organized as the input that the model was trained on. In addition, the SQLite queries must be transformed to the specific SQL dialect of the environment database.
To this end, we encapsulated the model with the following pre- and post- processing procedures (Figure 2):
Prompt Standardization: We based our inputs on Solid semantic models, extending the OmniSQL standard, augmenting it with enriched descriptions for each column and table, extended metric and query examples, and a schema summary. This provided the model with a clear and valuable interpretation of the schema.
The Transpilation Layer: SQL dialects have distinct functions and syntax. Since the Arctic SLM was trained on a specific SQLite dialect, generated SQL code requires transpilation (conversion) to the dialect of the target data warehouse. In this set of experiments we used Snowflake, so we developed a custom layer to handle query transpilation to Snowflake dialect.
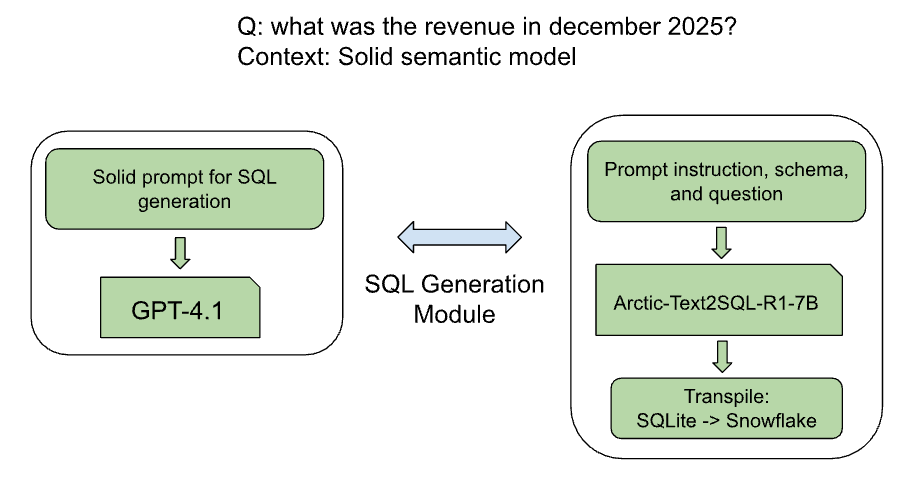
Results
For this experiment, we replaced the initial SQL generation module based on GPT models to a module based on the open source Snowflake/Arctic-Text2SQL-R1-7B small model (Figure 2). We used an internal evaluation benchmark comprising 137 couples of free text business questions and their related queries. Each agent performance was measured by executability, whether the generated SQL was able to execute successfully at the source system (Snowflake, in our case), and returned values alignment of the generated query to a reference (ground truth query).
The Arctic and baseline initial SQL generation was able to produce an executable SQL for 65% and 77% of questions, respectively. Understandably, most of the initial failures for the Arctic model were syntax errors, which were fixed after a single correction step. After completing the correction loops, both the Arctic and baseline models generated executable SQLs in a Snowflake dialect for 97% of questions. Additionally, there was not a significant difference in the generated SQLs retrieved values between the versions.
Conclusions and Future Work
Ultimately, this experiment demonstrates that specialized SLMs can rival industry giants when embedded within a robust agentic framework. By leveraging a modular loop of self-correction, the Snowflake/Arctic-7B model exceeded expectations, proving its performance is comparable to much larger models once initial errors are mitigated.
A key factor in this success was our use of Solid semantic models, which condensed large database schemas into enriched, high-signal summaries; this reduced the required context window and allowed the SLM to navigate complex data structures efficiently. Furthermore, using a SQLite-specialized base proved highly effective for generalizability; with the help of the transpilation layer, we narrowed the initial performance gap to just 12% due to syntax. This remaining delta was successfully closed during the fixing loop, resulting in nearly identical final executability. Moving forward, the true potential lies in database-specific fine-tuning, enabling these models to learn the unique nuances of individual datasets from the ground up.
 |
|