
Text2SQL vs. Semantic Layer? The real question is who does the modeling
dbt’s recent benchmark gets an important point right: this is not an either/or debate. But for enterprise teams, the real bottleneck is the work needed to generate, test and maintain semantic models.

Every few months, our industry rediscovers the same debate and presents it like a cage match: Text2SQL versus semantic layer.
dbt’s recent post, Semantic Layer vs. Text-to-SQL: 2026 Benchmark Update, is useful precisely because it moves the conversation forward. Instead of arguing from ideology, it argues from failure modes. And that is the right way to think about enterprise AI on top of data.
Their conclusion is also directionally right: both approaches matter. Text2SQL has gotten dramatically better. Semantic layers remain far more deterministic when the question is within scope. If accuracy matters, semantics win. If flexibility matters, Text2SQL still has an important role to play.
I agree with that.
But I think there is a more important conclusion hiding underneath their benchmark:
The real challenge is not Text2SQL or semantic layer. The real challenge is semantic model production.
The benchmark proves more than it says
The most interesting part of dbt’s post, in my opinion, is not just that the semantic layer performed better on modeled data.
It is that when coverage was missing, they added just three additional models, reran the benchmark, and suddenly the semantic layer could answer every question in scope, while Text2SQL improved too. That is a very important signal. It tells us that the bottleneck is not only reasoning quality. It is the system’s ability to create the right semantic structure, at the right time, for the right business question.
That is exactly where most enterprise projects get stuck.
On a whiteboard, “just build the semantic layer” sounds reasonable. In the real world, that means defining metrics, joins, dimensions, business definitions, tests, ownership, and maintenance processes across a living data stack that keeps changing. New tables appear. Existing logic shifts. Teams rename KPIs. Dashboards drift. Query patterns evolve.
So yes, the semantic layer is incredibly valuable. I wrote about that in The Two Souls of a Semantic Layer: A Tale of Governance and Insight. But the moment you say “semantic layer,” you also have to ask: who is building it, who is testing it, who is publishing it, and who is keeping it alive six months later?
That is where the theoretical debate becomes an operational one.
This is the part Solid is focused on
At Solid, our view has been consistent for a while.
In Data, Meet Business: Why You Need JIT Semantic Models, Instead of a Static Semantic Layer, I argued that static semantic models are too slow for a business that changes every week.
In The Ghost in the Machine: How Solid drastically accelerates semantic model generation, I explained part of the “how”: the logic of the business is often not fully captured in the schema itself. It lives in usage patterns, query history, BI assets, and the actual paths analysts take through the data.
That is why I think the future is not “Text2SQL alone,” and it is not “semantic layer alone,” either.
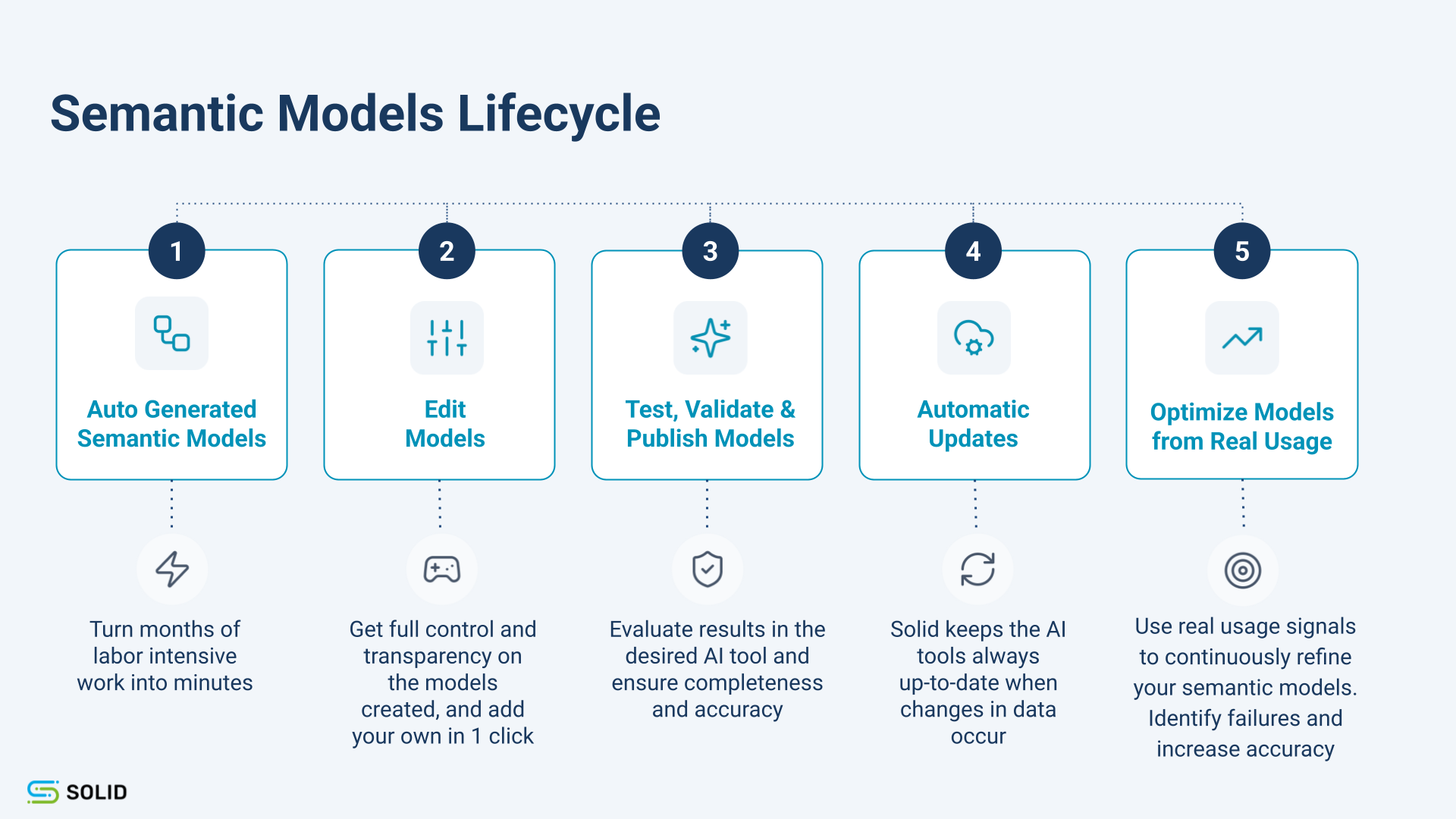
It is Text2SQL plus semantics, connected by an engine that continuously creates, tests and maintains the semantics themselves - even as data changes, usage evolves.
Publicly, that is exactly how we describe Solid Build: automatically turning warehouse usage, BI semantics, SQL query history, and metadata into semantic models; keeping them current as the data changes; letting teams review and approve them; and validating model logic before publication.
That matters because the enterprise problem is not proving that semantic layers work in a benchmark.
The enterprise problem is making enough of them, fast enough, with enough quality, and keeping them fresh enough, that the benchmark becomes your everyday reality.
The real architecture is not “vs.” It is “and, plus automation”
So when I read dbt’s post, my reaction is not disagreement. Quite the opposite. I think it confirms where the market is going.
How do you produce and maintain that modeling at enterprise scale?
If the answer is “a heroic manual effort by a small team of experts,” then the system will help in the demo and decay in production.
If the answer is “use AI to marry exploration and semantics, and automate the lifecycle of the semantic models themselves,” then you start to have something much more durable.
That is the architecture I believe in:
Text2SQL for exploration.
Semantics for determinism.
And an always-on semantic engineering layer that generates, tests, publishes, and maintains the bridge between them.
That, to me, is where this market is actually headed.
And that is why I think the most important question in 2026 is no longer “semantic layer or Text2SQL?”
It is:
Who is building the semantics, and how fast can they keep up with the business?