
From Universes to Agents: A Brief History of the Semantic Layer
Semantic Layers are all the rage... again... where did they come from, and why is this time different?

I’ve been around long enough to remember when semantic layer meant Universe Designer. In the 1990s BusinessObjects introduced a “universe” — a metadata model that hid SQL and let business people drag and drop their way through a relational database. If you worked in BI back then you probably spent months building one: picking tables, defining joins and measures, and praying the business wouldn’t change its mind.
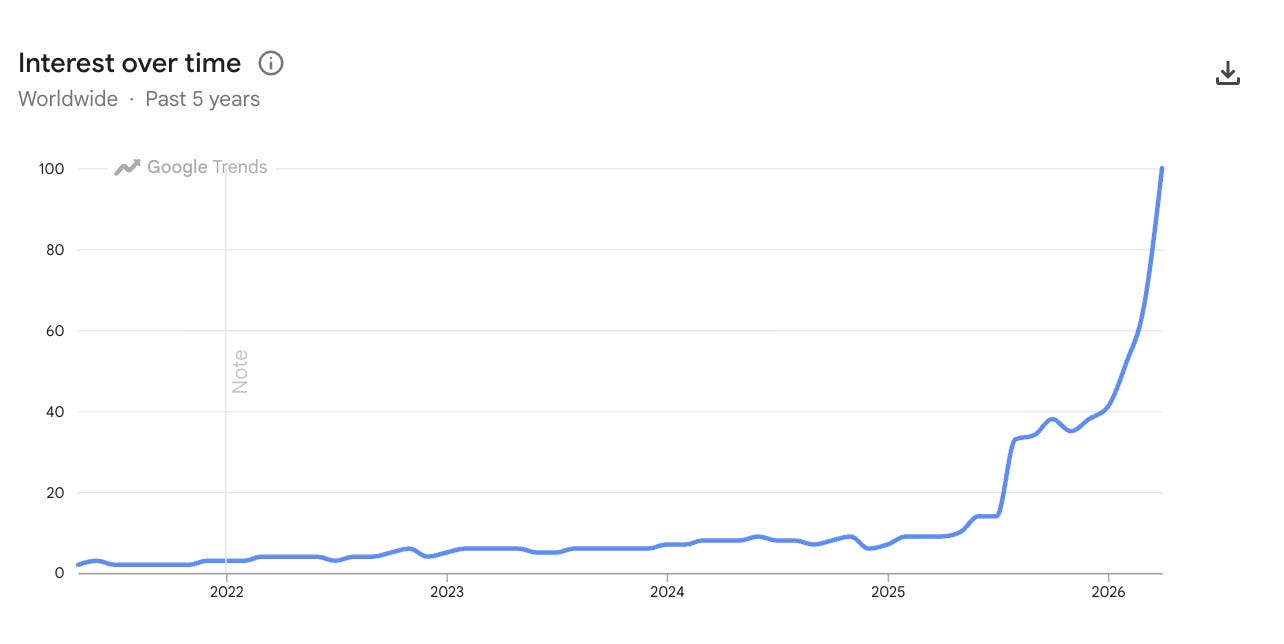
Three decades later that old idea has resurfaced. LinkedIn feeds and Gartner reports are buzzing about semantic layers. Google Trends shows a hockey‑stick curve for searches on the term. Why now? What changed? And what can the past teach us about the future?
Universes: hiding SQL from business users
The first commercially successful semantic layer was the Universe. BusinessObjects’ Universe Designer let developers build a metadata layer on top of relational databases. It mapped tables into business‑friendly objects and defined measures and dimensions so that users could query without writing SQL. The Universe acted as a bridge between raw data and people, abstracting complexity, providing governed access and enabling drag‑and‑drop analysis. For many enterprises in the 1990s and 2000s it became the backbone of reporting and budgeting.
But the early universes had limitations. They were tightly coupled to the BusinessObjects stack; building and updating them required specialised tooling; and each universe was tied to a single database. When SAP acquired BusinessObjects it introduced the UNX universe and Data Foundation to federate multiple sources. Even so, universes remained proprietary and slow to adapt. The lock-in was a major detractor. Teams needed faster answers, and self‑service BI promised agility.
Cubes and OLAP: pre‑aggregated semantics
At the same time, OLAP platforms like Microsoft Analysis Services and Hyperion Essbase defined hierarchies, measures and dimensions in cubes. Cubes pre‑aggregated data so queries were fast, and they embodied a kind of semantic layer by encoding business logic (e.g., calendars and product hierarchies). Yet they were also vendor‑specific and required ETL to flatten data into a multidimensional structure. They thrived in finance and supply‑chain planning but were less suited to the messy, evolving schemas of modern analytics.
Self‑service BI and the semantics vacuum
By the late 2000s a new mantra emerged: self‑service. Tools like Tableau and Qlik let analysts connect directly to databases, build their own dashboards and share insights without waiting on IT. This speed came at a cost: every team defined metrics differently. The shared context encoded in universes and cubes evaporated. Analysts wrote SQL with business logic sprinkled throughout; dashboards proliferated; definitions drifted. In other words, the semantic layer went away because it was too slow and too proprietary to keep up.
LookML, HANA and semantics as code
The next generation tried to marry agility with governance. Looker introduced LookML, a developer‑friendly language for defining dimensions, measures and joins in YAML. LookML treated semantics as code: version‑controlled, reusable and composable. But it was still locked inside the Looker ecosystem (now, the BigQuery ecosystem within Google Cloud).
SAP took a different approach with HANA. Its calculation views and Core Data Services (CDS) moved semantic modelling into the database itself, pushing down business logic for real‑time analytics. HANA’s semantic layer supported federated queries across universes, BW (BEx) queries and external systems. Despite these advances, semantics remained tied to particular vendors, and adoption was limited to enterprises deep in those stacks.
Semantics for purists, not for the business
One of the biggest failures of semantic layers was that no one, outside the data / BI team, cared about them. Data leaders would debate which semantic approach is best, and where you should manage your entities and their relationships.
But, the business didn’t care, and that meant that financially these endeavors would never take off. Companies built to fix the semantic layer problem struggled to get real traction, and saw their growth flatten out.
The context crisis: AI exposes the gap
Enter generative AI. Large language models (LLMs) can answer questions and generate analyses, but they don’t know what revenue means. When analysts ask natural‑language questions directly against a warehouse, LLMs often guess incorrectly; one study found that natural‑language queries against raw data were wrong in 80 % of cases. Without shared definitions, AI amplifies ambiguity and hallucinations.
On the flip side - well built semantic layers can generate massively reliable results, as dbt recently showed.
This context crisis is reigniting interest in semantic layers. Instead of hiding SQL from humans, the new goal is to teach machines what data means. AI‑driven analytics require deterministic definitions, machine‑enforceable relationships and real‑time governance. The old universes were built for reporting. The new semantic layers are built for agents.
What’s different this time?
Several things make today’s semantic layers more than a repeat of the past:
Open and headless. Modern semantic layers are decoupled from any one BI tool. They expose definitions via open APIs (MCP, REST, GraphQL) so that agents, dashboards, notebooks, AI-assisted coding and chatbots can all consume the same context.
Machine‑enforceable semantics. Definitions are not just documentation; they are executed automatically. When a query references net revenue, the layer applies the correct joins, filters and security policies without the analyst having to remember them, nor the business user needing to know them.
Federated and composable. Unlike early universes, modern layers can sit on top of multiple warehouses, vector stores and knowledge graphs. They let you define semantics once and use them everywhere, even across platforms.
Driven by AI. The killer application is no longer drag‑and‑drop reporting; it’s AI copilots and agents that need trustworthy data to automate tasks and decisions. Research shows that grounding LLMs in a semantic layer increases accuracy by more than 3×.
In short, we’re not going back to 1992. We’re building something new: a universal, open semantic layer that acts as the control plane for both humans and machines.
The new role: semantic engineering
All of this raises a people question. In the old days the Universe designer sat in IT and rarely interacted with the business. Today, someone needs to own your company’s semantic layer and continuously align it with reality. That person might be a finance lead who knows the nuances of ARR, an operations manager who understands edge cases, or an analytics engineer who curates dbt models. Naming them semantic engineers gives them a mandate: codify the business logic that AI depends on.
Their job isn’t just to build dashboards; it’s to maintain a living semantic model that exposes metrics, relationships and policies to every tool and agent. Success is measured by how reliably AI operates across the enterprise, not by how many reports they ship.
Writing SQL code by hand will be gone by the end of 2026. Maintaining semantic models will be the new norm.
Lessons from history — and how to start
The history of semantic layers teaches us three things:
Abstraction matters. Universes and cubes were successful because they hid complexity and empowered non‑technical users.
Coupling kills adoption. They fell out of favor because they were tightly bound to proprietary tools. As the stack diversified, semantics didn’t keep up.
Context is infrastructure. The AI era demands deterministic, governed semantics. Without them, LLMs hallucinate and agents do the wrong thing.
If you want to build a semantic layer today, start small. Pick a domain where metric drift causes pain; nominate a semantic engineer; generate a first model using existing SQL and BI assets (Solid can automate this for you); then iterate. Treat semantics as code, version it, and share it via MCP. Learn from the history and avoid the coupling mistakes of the past.
If you’d like to see a modern semantic layer in action, get a demo. We’ll show you how Solid generates and maintains a universal semantic layer on top of your data so that humans and AI can finally speak the same language.